1> opensource Gemmini git repository 주소 : https://github.com/ucb-bar/gemmini
2> Gemmini를 이해하기 위해서 본인이 접근 할 순서는 다음과 같다.
1) Overall data flow and objective
2) Parameters에 대한 분석
3-1) Major Components overviewing
3-1) Chisel/Scala 세부 모듈에 대한 Testablity를 확보한 Code following
4) Software Test
1) Overall data flow and objective
Gemmini
The Gemmini project is developing a full-system, full-stack DNN hardware exploration and evaluation platform. Gemmini enables architects to make useful insights into how different components of the system and software stack (outside of just the accelerator itself) interact to affect overall DNN performance.
Gemmini is part of the Chipyard ecosystem, and was developed using the Chisel hardware description language.
This document is intended to provide information for beginners wanting to try out Gemmini, as well as more advanced in-depth information for those who might want to start hacking on Gemmini's source code.
- 해당 코드와 프로세스에 대해 이해하게 되었을 때, DNN 동작에 있어 full stack(hardware - software)에 대한 전반적인 이해(full stack)를 할 수 있다는 의미이며, Chisel-HDL를 사용한 Chipyard ecosystem을 이용한다
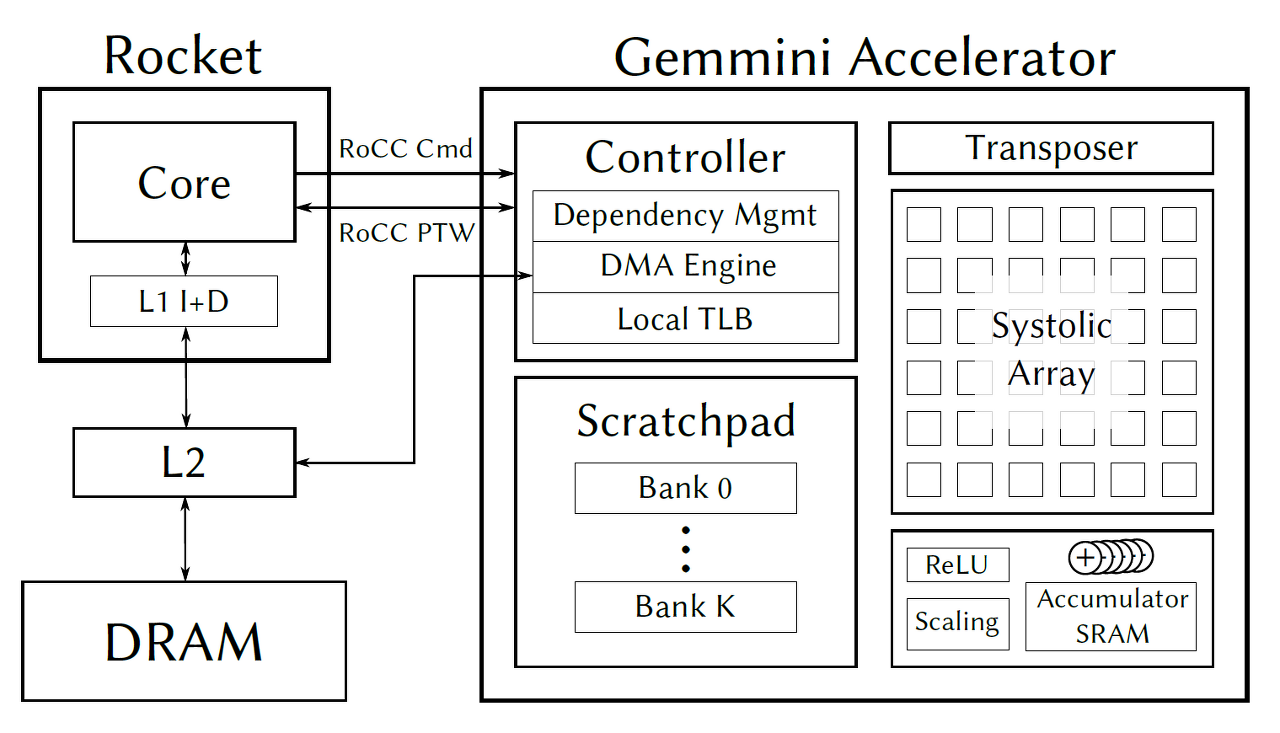
Architecture
1> Gemmini is implemented as a RoCC accelerator with non-standard RISC-V custom instructions.
2> The Gemmini unit uses the RoCC port of a Rocket or BOOM tile, and by default connects to the memory system through the System Bus (i.e., directly to the L2 cache).
3> At the heart of the accelerator lies a systolic array that performs matrix multiplications. By default, the matrix multiplication supports both output-stationary and weight-stationary dataflows, which programmers can pick between at runtime. However, the dataflow can also be hardened at elaboration time.
4> The systolic array's inputs and outputs are stored in an explicitly managed scratchpad, made up of banked SRAMs.
5> A DMA engine facilitates the transfer of data between main memory (which is visible to the host CPU) and the scratchpad. Because weight-stationary dataflows require an accumulator outside the systolic array, we add a final SRAM bank, equipped with adder units, which can be conceptually considered an extension of the scratchpad memory space. The systolic array can store results to any address in the accumulator, and can also read new inputs from any address in the accumulator. The DMA engine can also transfer data directly between the accumulator and main memory, which is often necessary to load in biases.
Gemmini also includes peripheral circuitry to optionally apply activation functions such as ReLU or ReLU6, scale results down by powers-of-2 to support quantized workloads, or to transpose matrices before feeding them into the systolic array to support the output-stationary dataflow.
*systolic : (심장) 수축
*output-stationary dataflow : 출력 고정 데이터 flow
1> Gemmini는 RISC-V custom instructions를 지원하는 RoCC accelerator로 구현되는 프로젝트이다.
2> Rocket나 BOOM tiles를 사용하여 memory system을 연결한다(Rocket bus 인 tilelink를 사용하는 듯... 코드를 봐야 알 것같음)
3> accelerator 핵심은 systolic array이 어떤 식으로 동작할지를 설계하는 것이다. 이는 multiplication 를 수행하는 matrix이며 OS, WS라는 output-stationary and weight-stationary dataflows를 지원하고 이를 programmer들은 실시간으로 이를 picking하며 컨트롤할 수 있다. 그러나, dataflow는 elaboration time( .scala -> .v 로 제너레이팅 되는 시점)에 고정되어 바꿀수 없다.
4> SRAM들로 banked된 scratchpad에 의해 systolic array의 input / output이 명시적으로 stored된다.
5> DMA engine facilitates는 main mory와 scratchpad 사이의 데이터 전송을 담당한다. weight-stationary dataflows는 systolic array 외부에 있는 accumulator가 필요하기 때문에, adder unit들이 equipped 된최종 SRAM bank를 추가하는데, 이는 개념적으로 scratchpad memory space의 확장된 구조라고 생각할 수 있다. systolic array는 any address in accumulator에 이러한 results를 내보낼 수 있다. 또한 any address in accumulator에서 오는 것을 읽을 수 도 있다. (종종 biases를 Systolic Array에 불러올 필요가 있으므로) DMA engines는 the accumulator와 main memory에 대한 데이터 교환을 directly 할 수 있는 기능이 갖추어져있다.
6> gemmini는 RELU나 RELU6를 optionally activate할 수 있는 peripheral circuitry(주변 회로)를 포함하고 있으며, 이는 2제곱승으로 scaling quantize할 수 있거나 OS flow를 지원하기 위해 Systolic Array에 공급하기 전에 matrices을 transpose할 수 있도록 되어있다.

RoCC interface에 대한 설명 : https://inst.eecs.berkeley.edu/~cs250/sp17/disc/lab2-disc.pdf
2) Parameters
구조 설계를 위해서는 어떠한 파라미터가 있어야할 지를 알아야한다. 따라서 아래의 설명을 따라 필요한 파라미터가 무엇인지를 알고 있어야함.
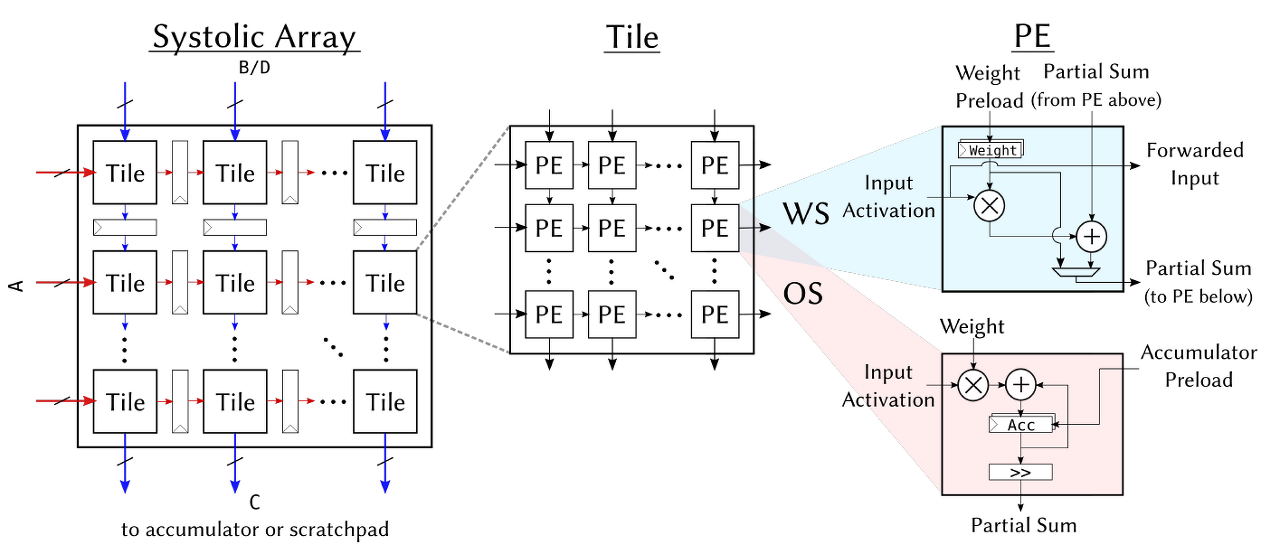
- Systolic array dimensions (tileRows, tileColumns, meshRows, meshColumns): The systolic array is composed of a 2-level hierarchy, in which each tile is fully combinational, while a mesh of tiles has pipeline registers between each tile
- Systolic array는 2-level 계층 구조로 되어있으며, 그 두 계층인 Tile과 Mesh에 대한 크기를 결정한다. 각각의 tile은 fully combinational 하며 그 사이엔 pipleline register가 있도록 설계되어있다(configure, inside of Accelator를 참조) - Dataflow parameters (dataflow): Determine whether the systolic array in Gemmini is output-stationary or weight-stationary, or whether it supports both dataflows so that programmers may choose between them at runtime.
- Gemmini 안에 있는 systolic array가 OS인지, WS인지, 아니면 그 둘다 인지를 체크한다. - Scratchpad and accumulator memory parameters (sp_banks, sp_capacity, acc_capacity): Determine the properties of the Gemmini scratchpad memory: overall capacity of the scratchpad or accumulators (in KiB), and the number of banks the scratchpad is divided into.
- 메모리의 capacity와 몇개의 bank를 가질지를 결정한다.
- Type parameters (inputType, outputType, accType): Determine the data-types flowing through different parts of a Gemmini accelerator. For example, inputType may be an 8-bit fixed-point number, while accType, which determines the type of partial accumulations in a matrix multiplication, maybe a 32-bit integer. outputType only determines the type of data passed between two processing elements (PEs); for example, an 8-bit multiplication may produce a 16-bit result which must be shared between PEs in a systolic array.
- gemmini accelerator에 흐르는 다양한 부분에서의 데이터 타입을 결정한다. 예를 들어 accType은 partial accumulation in a matrix multiplication에서 사용되는 데이터타입을 inputType과 다르게 둘 수 있다. outputType은 PE 사이를 pass하는 데이터 타입만을 결정한다.
Examples of possible datatypes are:- SInt(8.W) for a signed 8-bit integer
- UInt(32.W) for an unsigned 32-bit integer
- Float(8, 24) for a single-precision IEEE floating point number
- If your datatype is a floating-point number, then you might also want to change the pe_latency parameter, which specifies how many shift registers to add inside the PEs. This might be necessary if your datatype cannot complete a multiply-accumulate operation within a single cycle.
- single cycle 안에 multiply-accumulate operation 이 돌지 않는 경우에 둘 수 있는 shift register를 얼마나 PE 안쪽에서 삽입할 지를 pe_latency 파라미터를 조정하여 결정할 수 있다.
- Access-execute queue parameters (ld_queue_length, st_queue_length, ex_queue_length, rob_entries): To implement access-execute decoupling, a Gemmini accelerator has a load instruction queue, a store instruction queue, and an execute instruction queue. The relative sizes of these queue determine the level of access-execute decoupling. Gemmini also implements a reorder buffer (ROB) - the number of entries in the ROB determines possible dependency management limitations.
- access-execute decoupling이식을 위해 a load instruction queue, a store instruction queue, and an execute instruction queue 3개의 큐를 가진다. 상대적인 size는 access-execute decoupling레벨에 따라 결정되고 reorder buffer에 의해 이러한 limitations이 controlled 된다(해당 부분은 추후에 코드를 보면 더 자세히 이해가 될 것 같음)
- DMA parameters (dma_maxbytes, dma_buswidth, mem_pipeline): Gemmini implements a DMA to move data from main memory to the Gemmini scratchpad, and from the Gemmini accumulators to main memory. The size of these DMA transactions is determined by the DMA parameters. These DMA parameters are tightly coupled with Rocket Chip SoC system parameters: in particular dma_buswidth is associated with the SystemBusKey beatBytes parameter, and dma_maxbytes is associated with cacheblockbytes Rocket Chip parameters.
- DRAM(main memory)에서 Scratchpad로 데이터를 전송하는 DMA에 대한 파라미터임
There are also optional features, which can be either enabled or left out of Gemmini at elaboration-time. For example:
- Scaling during "move-in" operations (mvin_scale_args, mvin_scale_acc_args): When data is being moved in from DRAM or main memory into Gemmini's local scratchpad memory, it can optionally be multiplied by a scaling factor. These parameters specify what the datatype of the scaling factor is, and how the scaling is actually done. If these are set to None, then this optional feature will be disabled at elaboration time. If both the scratchpad inputs are accumulator inputs are to be scaled in the same say, then the mvin_scale_shared parameter can be set to true so that the multipliers and functional units are shared.
- 해당 부분은 optional feature로서, data가 DRAM에서 Main memory에서 move 될때 scaling을 하는 등의 optional을 제공하는 feature이다.
+1) CodeReview Step :
설명 중간중간 Code에 대한 review를 삽입함.
해당 구조는 https://github.com/yoonhyeonjoon/gemminiProject 에 branch를 통해 step별로 나누어 놓았으며 Unit Test 혹은 각 unit별 elaborate 코드를 삽입하여 구현할 계획임.
최소유닛 PE에서 바라본 code view는 아래 플로우와 같다.
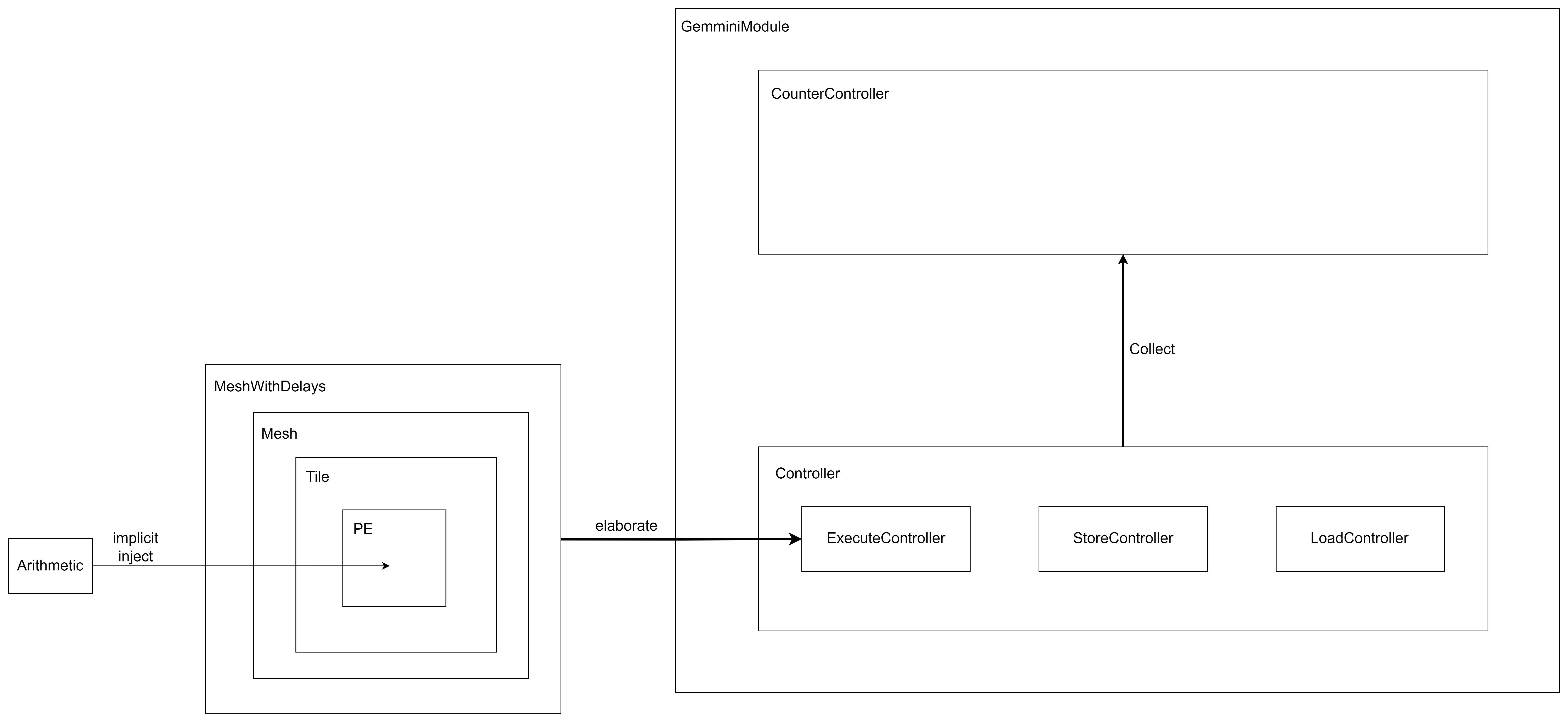
Arithmetic.scala
overflow를 체크하는 코드
//for UInt usecase
override def clippedToWidthOf(t: UInt) = {
val sat = ((1 << (t.getWidth-1))-1).U
Mux(self > sat, sat, self)(t.getWidth-1, 0)
}
즉, t 의 width에 dependent하게 self로 들어온 value의 overflow를 처리한다.
'SystemVerilog' 카테고리의 다른 글
| Automatic/Ref/Inout 에 대한 고찰 (0) | 2019.12.06 |
|---|
