https://developer.android.com/kotlin/flow?hl=ko
참고 : https://two22.tistory.com/16
Kotlin Flow #1 - 기본 사용법
Flow 란? 코틀린 플로우는 suspend function을 보완하기 위해 나온 친구이다. 비동기 동작의 결과로 suspend function 이 하나의 결과물 던진다면, 플로우를 이용하여 여러 개의 결과를 원하는 형식으로 던
two22.tistory.com
Android의 Kotlin 흐름 | Android 개발자 | Android Developers
코루틴에서 흐름은 단일 값만 반환하는 정지 함수와 달리 여러 값을 순차적으로 내보낼 수 있는 유형입니다. 예를 들면 흐름을 사용하여 데이터베이스에서 실시간 업데이트를 수신할 수 있습니
developer.android.com
In coroutines, a flow is a type that can emit multiple values sequentially, as opposed to suspend functions that return only a single value. For example, you can use a flow to receive live updates from a database.
flow는 코루틴 위에 구축되며 여러 값을 제공할 수 있습니다. flow는 개념적으로 비동기식으로 계산할 수 있는 데이터 스트림입니다 . 내보낸 값은 같은 유형이어야 합니다. 예를 들어, a Flow<Int>는 정수 값을 내보내는 흐름입니다.
비동기 동작의 결과로 suspend function 이 하나의 결과물 던진다면, 플로우를 이용하여 여러 개의 결과를 원하는 형식으로 전달할 수 있습니다.
흐름은 값 시퀀스를 생성하는 Iterator와 매우 비슷하지만 정지 함수를 사용하여 값을 비동기적으로 생성하고 사용합니다. 예를 들어 흐름은 기본 스레드를 차단하지 않고 다음 값을 생성할 네트워크 요청을 안전하게 만들 수 있습니다.
데이터 스트림에는 다음과 같은 세 가지 항목이 있습니다.
- 생산자는 스트림에 추가되는 데이터를 생산합니다. 코루틴 덕분에 흐름에서 비동기적으로 데이터가 생산될 수도 있습니다.
- (선택사항) 중개자는 스트림에 내보내는 각각의 값이나 스트림 자체를 수정할 수 있습니다.
- 소비자는 스트림의 값을 사용합니다.
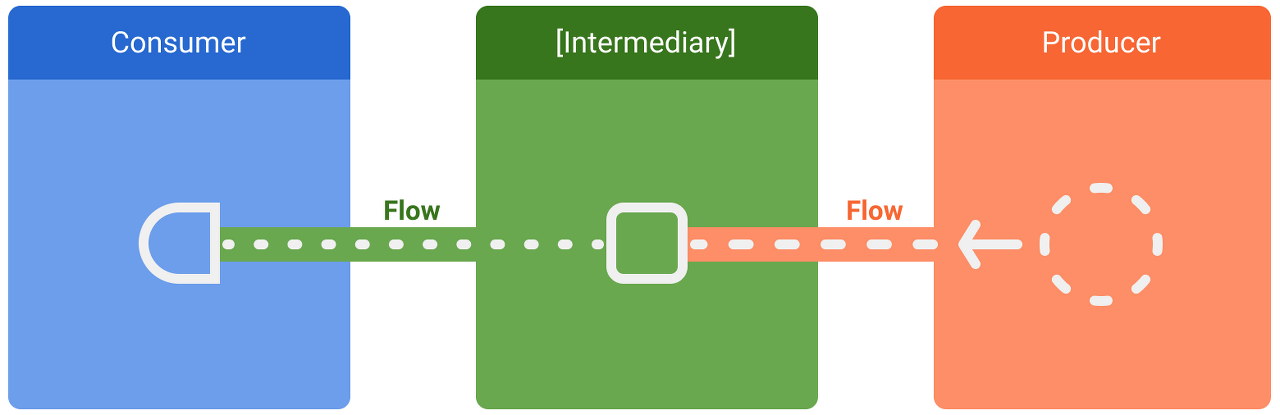
Android에서 데이터 소스 또는 저장소는 일반적으로 UI 데이터 생산자입니다. 이때 View는 최종적으로 데이터를 표시하는 소비자입니다. View 레이어가 사용자 입력 이벤트의 생산자이고 계층 구조의 다른 레이어가 이 이벤트를 사용하는 경우도 있습니다. 생산자와 소비자 사이의 레이어는 일반적으로 다음 레이어의 요구사항에 맞게 조정하기 위해 데이터 스트림을 수정하는 중개자의 역할을 합니다.
흐름 만들기
흐름을 만들려면 흐름 빌더 API를 사용합니다. flow 빌더 함수는 emit 함수를 사용하여 새 값을 수동으로 데이터 스트림에 내보낼 수 있는 새 흐름을 만듭니다.
다음 예에서 데이터 소스는 고정된 간격으로 최신 뉴스를 자동으로 가져옵니다. 정지 함수는 연속된 값을 여러 개 반환할 수 없으므로, 데이터 소스가 이러한 요구사항을 충족하는 흐름을 만들고 반환합니다. 이 경우 데이터 소스가 생산자의 역할을 합니다.
Flow builders
There are the following basic ways to create a flow:
- flowOf(...) functions to create a flow from a fixed set of values.
- asFlow() extension functions on various types to convert them into flows.
- flow { ... } builder function to construct arbitrary flows from sequential calls to emit function.
- channelFlow { ... } builder function to construct arbitrary flows from potentially concurrent calls to the send function.
- MutableStateFlow and MutableSharedFlow define the corresponding constructor functions to create a hot flow that can be directly updated.
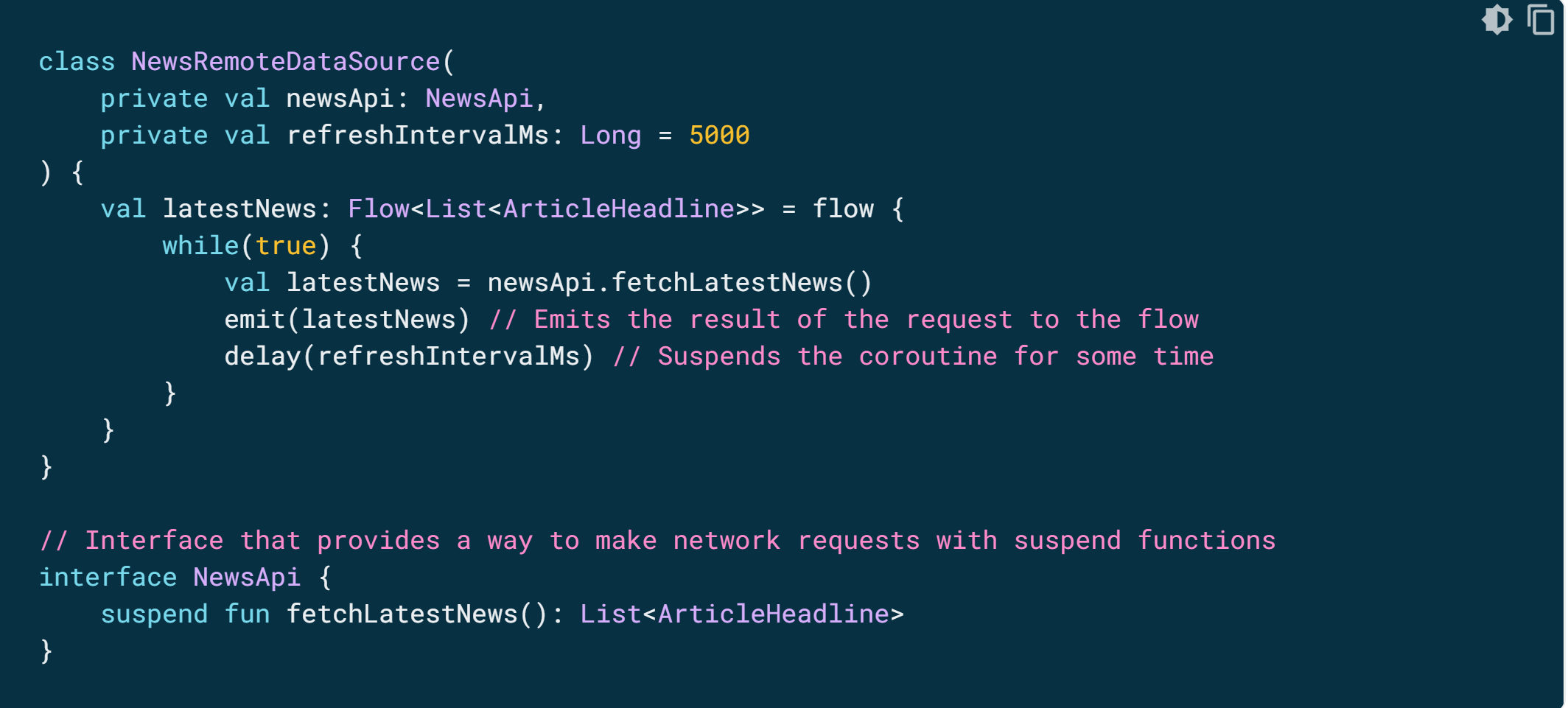
flow 빌더는 코루틴 내에서 실행됩니다. 따라서 동일한 비동기 API의 이점을 활용할 수 있지만 몇 가지 제한사항이 적용됩니다.
- 흐름이 순차적입니다. 생산자가 코루틴에 있으므로, 정지 함수를 호출하면 생산자는 정지 함수가 반환될 때까지 정지 상태로 유지됩니다. 이 예에서 생산자는 fetchLatestNews 네트워크 요청이 완료될 때까지 정지됩니다. 그런 다음에만 결과를 스트림으로 내보냅니다.
- flow 빌더에서는 생산자가 다른 CoroutineContext의 값을 emit할 수 없습니다. 그러므로 새 코루틴을 만들거나 코드의 withContext 블록을 사용하여 다른 CoroutineContext에서 emit를 호출하지 마세요. 이런 경우 callbackFlow 같은 다른 흐름 빌더를 사용할 수 있습니다.
위 코드는 "생산자"입니다.
flow 생성 보충 :

스트림 수정
중개자는 중간 연산자를 사용하여 값을 소비하지 않고도 데이터 스트림을 수정할 수 있습니다. 이 연산자는 데이터 스트림에 적용되는 경우 값이 향후에 사용될 때까지 실행되지 않을 작업 체인을 설정하는 함수입니다. 흐름 참고 문서에서 중간 연산자에 관해 자세히 알아보세요.
아래 예에서 저장소 레이어는 중간 연산자 map을 사용하여 데이터가 View에 표시되도록 변환합니다.
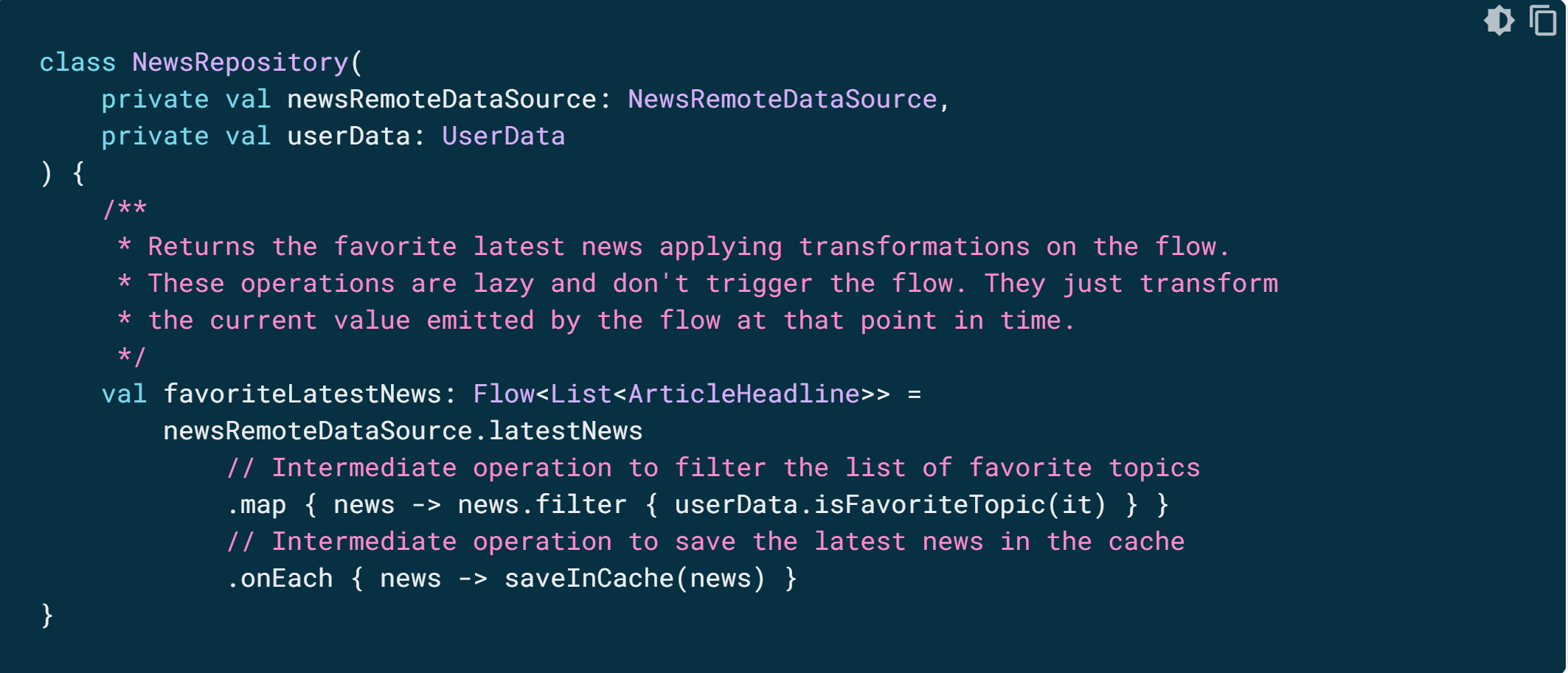
중간 연산자는 시차를 두고 차례로 적용할 수 있어 항목을 흐름에 내보낼 때 느리게 실행되는 작업 체인을 구성할 수 있습니다. 스트림에 중간 연산자를 적용하는 것만으로 흐름 수집(flow collect)이 시작되지는 않습니다.
흐름에서 수집(collect)
터미널 연산자를 사용하여 값 수신 대기를 시작하는 흐름을 트리거합니다. 내보낼 때 스트림의 모든 값을 가져오려면 collect를 사용합니다. 터미널 연산자에 관해서는 흐름 관련 공식 문서에서 자세히 알아볼 수 있습니다.
collect는 suspend function이므로 코루틴 내에서 실행해야 합니다. 모든 새 값에서 호출되는 매개변수로 람다를 사용합니다. 정지 함수이므로, collect를 호출하는 코루틴은 흐름이 종료될 때까지 정지될 수 있습니다.
이전 예에서 저장소 레이어의 데이터를 사용하는 ViewModel을 간단히 구현하면 다음과 같습니다.

흐름을 수집하면 고정된 간격으로 최신 뉴스를 새로고침하고 네트워크 요청 결과를 내보내는 생산자가 트리거됩니다. 생산자는 while(true) 루프로 항상 활성 상태가 유지되므로 ViewModel이 삭제되어 viewModelScope가 취소되면 데이터 스트림이 종료됩니다.
다음과 같은 이유로 흐름 수집이 중지될 수 있습니다.
- 이전 예시에 나온 것처럼 수집된 코루틴이 취소된 경우. 이 경우 기본 생산자도 중지됩니다.
- 생산자가 항목 방출을 완료한 경우. 이 경우 데이터 스트림이 종료되고 collect를 호출한 코루틴이 실행을 다시 시작합니다.
다른 중간 연산자를 통해 지정되지 않은 경우 흐름의 상태는 콜드 및 지연입니다. 즉, 흐름에서 터미널 연산자가 호출될 때마다 생산자 코드가 실행됩니다. 이전 예시에서 흐름 수집기가 여러 개 있으면 데이터 소스가 서로 다른 고정된 간격으로 최신 뉴스를 여러 번 가져옵니다. 여러 소비자가 동시에 수집할 때 흐름을 최적화하고 공유하려면 shareIn 연산자를 사용합니다.
예상치 못한 예외 포착
생산자 구현은 타사 라이브러리에서 가져올 수 있습니다. 따라서 예기치 않은 예외가 발생할 수 있습니다. 이러한 예외를 처리하려면 catch 중간 연산자를 사용합니다.
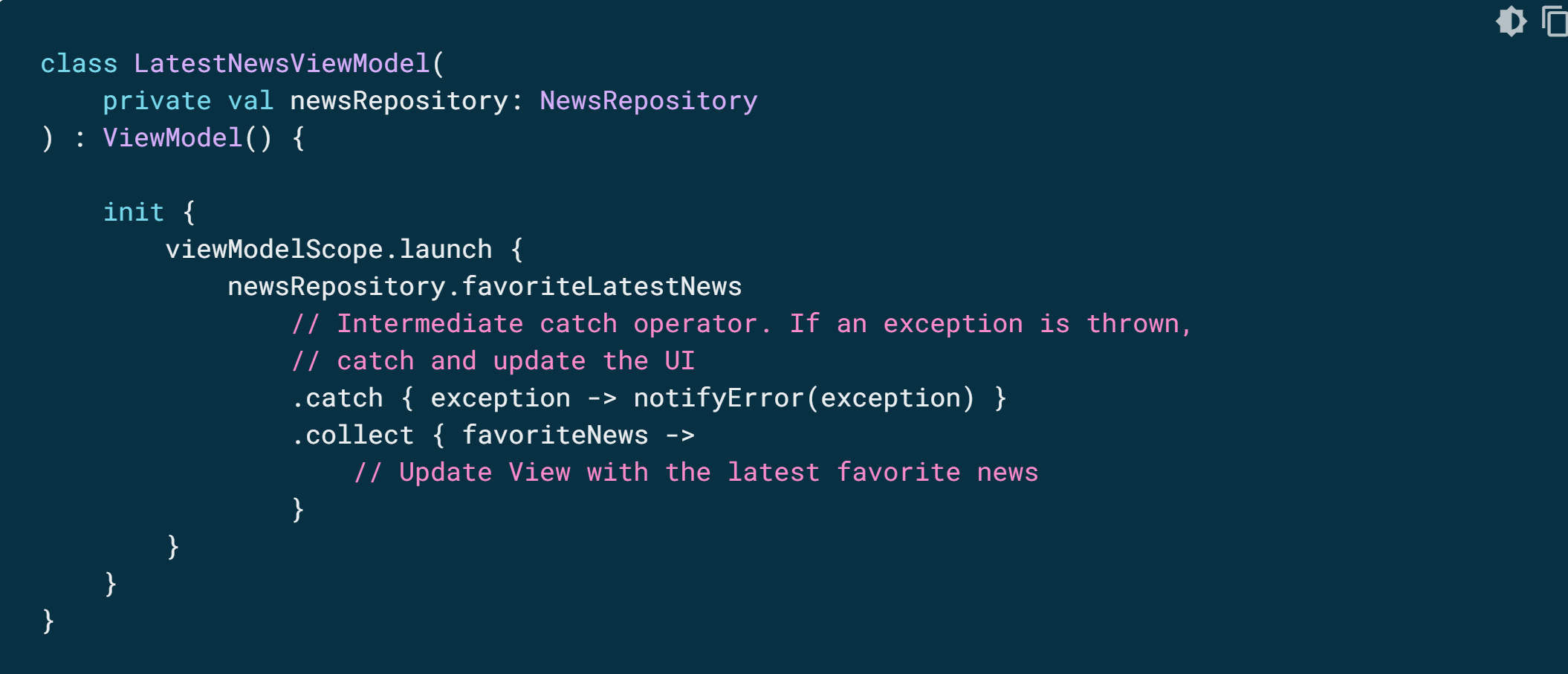
이전 예시에서 예외가 발생하는 경우 새 항목이 수신되지 않았기 때문에 collect 람다가 호출되지 않습니다.
catch는 항목을 흐름에 emit할 수도 있습니다. 대신 예제 저장소 레이어는 캐시된 값을 emit할 수 있습니다.
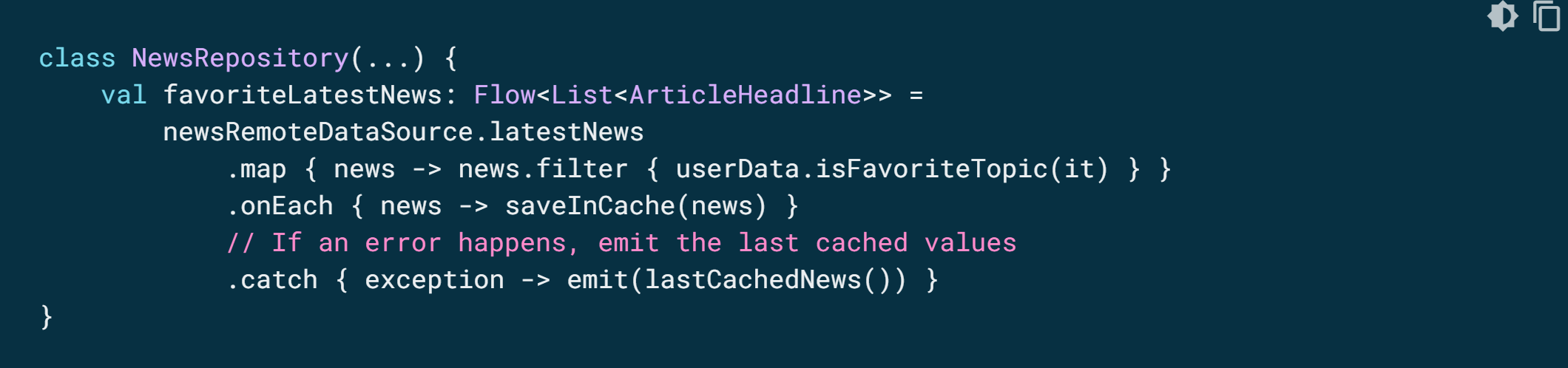
이 예에서는 예외가 발생하면 collect 람다가 호출되므로 예외로 인해 새 항목이 스트림에 내보내집니다.
다른 CoroutineContext에서 실행하기
기본적으로 flow 빌더의 생산자는 수집하는 코루틴의 CoroutineContext에서 실행됩니다. 앞에서 언급한 것처럼 다른 CoroutineContext에서 값을 emit할 수 없습니다. 이 동작은 경우에 따라 원하지 않는 동작일 수도 있습니다. 예를 들어, 이 주제 전체에 사용된 예에서 저장소 레이어는 viewModelScope가 사용하는 Dispatchers.Main에서 작업을 실행하면 안 됩니다.
흐름의 CoroutineContext를 변경하려면 중간 연산자 flowOn을 사용합니다. flowOn은 업스트림 흐름의 CoroutineContext를 변경합니다. 즉, 생산자 및 중간 연산자가 flowOn 전에(또는 위에) 적용됩니다. 다운스트림 흐름(flowOn 이후의 중간 연산자 및 소비자)은 영향을 받지 않으며 흐름에서 collect하는 데 사용되는 CoroutineContext에서 실행됩니다. flowOn 연산자가 여러 개 있는 경우 각 연산자는 현재 위치에서 업스트림을 변경합니다.
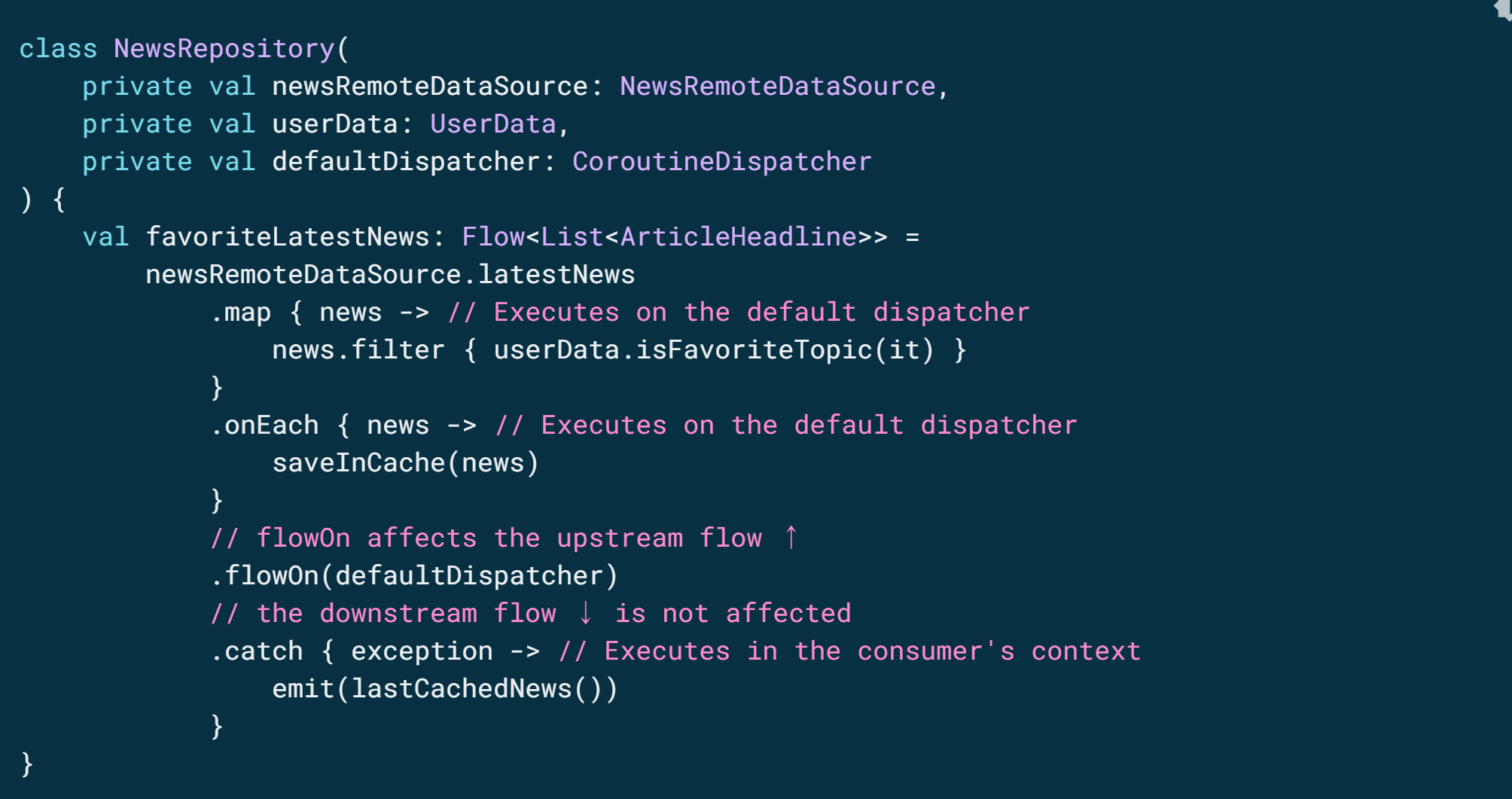
이 코드에서 onEach 및 map 연산자는 defaultDispatcher를 사용하는 반면, catch 연산자와 소비자는 viewModelScope에 사용되는 Dispatchers.Main에서 실행됩니다.
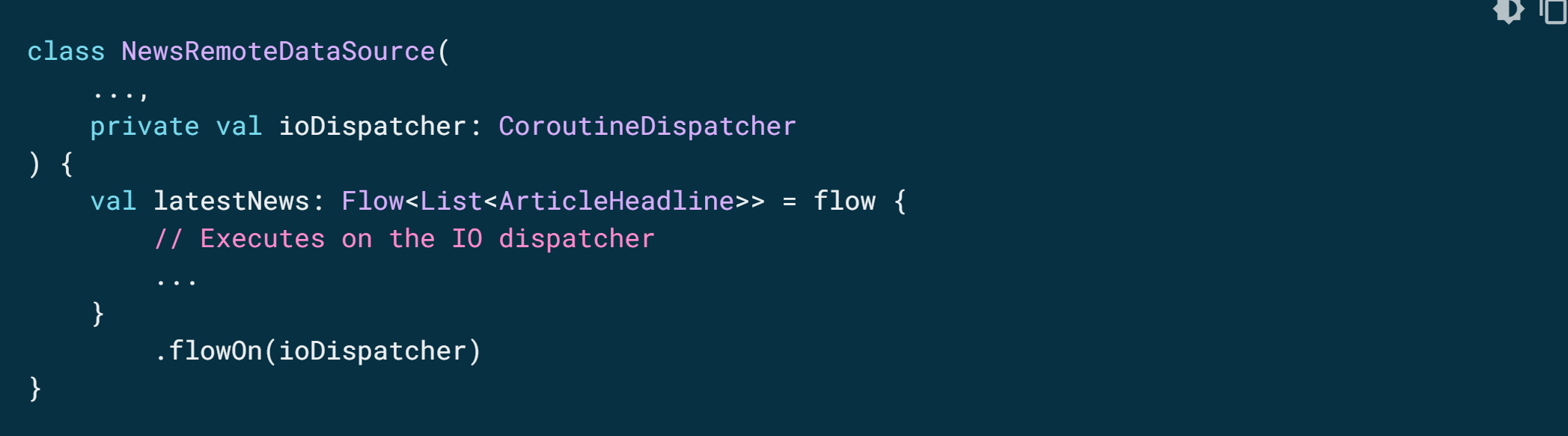
데이터 소스 레이어가 I/O 작업을 수행하므로, I/O 작업에 최적화된 디스패처를 사용해야 합니다.
콜백 기반 API를 흐름으로 변환
callbackFlow는 콜백 기반 API를 흐름으로 변환할 수 있는 흐름 빌더입니다. 예를 들어 Firebase Firestore Android API는 콜백을 사용합니다. 이 API를 흐름으로 변환하고 Firestore 데이터베이스 업데이트를 수신 대기하려면 다음 코드를 사용하면 됩니다.

flow 빌더와 달리 callbackFlow에서는 send 함수를 사용하여 다른 CoroutineContext에서 값을 내보내거나 offer 함수 사용하여 코루틴 외부로 값을 내보낼 수 있습니다.
내부적으로 callbackFlow는 개념상 차단 큐와 매우 유사한 채널을 사용합니다. 채널은 버퍼링 가능한 요소의 최대 수인 용량으로 구성됩니다. callbackFlow에서 생성된 채널의 기본 용량은 요소 64개입니다. 전체 채널에 새 요소를 추가하려는 경우 send는 새 요소를 위한 공간이 생길 때까지 생산자를 정지하는 반면, offer는 채널에 요소를 추가하지 않고 즉시 false를 반환합니다.
'Android Dev' 카테고리의 다른 글
| Compose - keyboard Setting (0) | 2021.10.06 |
|---|---|
| Compose - Thread Timeout 타임아웃 구현 (0) | 2021.09.06 |
| ContentController/SelectContentsDialogfragment사용 (0) | 2021.07.02 |
| Databinding Error Log Following (0) | 2021.05.30 |
| CoordinatorLayout 기억할바 (0) | 2021.05.29 |
