0> Coroutines guide
Coroutines guide | Kotlin
kotlinlang.org
1> kotlin은 async, await 가 standard library에 없고, suspending function 또한 future, promises에 비해 관리가 복잡하다.
2> kotlinx.coroutines library에 다양한 구현이 있으니 이를 사용하자
1> Coroutines basics
1. 코루틴은 어느 한 스레드에 종속되지않고 이리저리 옮겨다니면서 실행되는 computation suspend 기능을 갖춘 인스턴스다
2. 런치는 코루틴을 생성한다. 코드 블록내에서 런치 블록은 독립적으로 동작한다
3. 런블록킹은 코루틴블록이 아닌 공간에 코루틴이 동작하는 가교역할을 하는 코루틴 빌더이다
4. 런블록킹은 비용이 큰 일이며, 어플리케이션의 탑 레벨에서 주로 사용할 수 있으며, 코드 내부에서 사용하는 것은 자제해야한다.
5. 서드펜드 함수는 코루틴 블록 내에서 동작하며 다른 서드펜드 함수를 사용할 수 있다.
6. runBlocking은 작업이 끝날때까지 현재 스레드를 blocking한다. 반면에, coroutineScope는 (다른 사용을 위해) 스레드를 blocking하지않고 단지 suspend만 한다. 따라서 coroutineScope는 suspending Function의 어디에서 사용할 수 있다.
7. coroutineScope안에서 launch 된 것은 동시에 실행된다.
8. launch block은 job을 리턴하며, 외부에서 이를 호출할 수 있다.
9. 코루틴은 경량쓰레드이므로 다수의 코루틴 블록을 lauch해도 문제없다
https://kotlinlang.org/docs/coroutines-basics.html#your-first-coroutine
This section covers basic coroutine concepts.
Your first coroutine
A coroutine is an instance of suspendable computation. It is conceptually similar to a thread, in the sense that it takes a block of code to run that works concurrently with the rest of the code. However, a coroutine is not bound to any particular thread. It may suspend its execution in one thread and resume in another one.
Coroutines can be thought of as light-weight threads, but there is a number of important differences that make their real-life usage very different from threads.
Run the following code to get to your first working coroutine:
1> 코루틴은 어느 한 스레드에 종속되지않고 이리저리 옮겨다니면서 실행되는 computation suspend 기능을 갖춘 인스턴스다
fun main() = runBlocking { // this: CoroutineScope
launch { // launch a new coroutine and continue
delay(1000L) // non-blocking delay for 1 second (default time unit is ms)
println("World!") // print after delay
}
println("Hello") // main coroutine continues while a previous one is delayed
}
출력결과
Hello
World!
launch is a coroutine builder. It launches a new coroutine concurrently with the rest of the code, which continues to work independently. That's why Hello has been printed first.
delay is a special suspending function. It suspends the coroutine for a specific time. Suspending a coroutine does not block the underlying thread, but allows other coroutines to run and use the underlying thread for their code.
runBlocking is also a coroutine builder that bridges the non-coroutine world of a regular fun main() and the code with coroutines inside of runBlocking { ... } curly braces. This is highlighted in an IDE by this: CoroutineScope hint right after the runBlocking opening curly brace.
If you remove or forget runBlocking in this code, you'll get an error on the launch call, since launch is declared only in the CoroutineScope:
The name of runBlocking means that the thread that runs it (in this case — the main thread) gets blocked for the duration of the call, until all the coroutines inside runBlocking { ... } complete their execution. You will often see runBlocking used like that at the very top-level of the application and quite rarely inside the real code, as threads are expensive resources and blocking them is inefficient and is often not desired.
1> 런치는 코루틴을 생성한다. 코드 블록내에서 런치 블록은 독립적으로 동작한다
2> 런블록킹은 코루틴블록이 아닌 공간에 코루틴이 동작하는 가교역할을 하는 코루틴 빌더이다
The name of runBlocking means that the thread that runs it (in this case — the main thread) gets blocked for the duration of the call, until all the coroutines inside runBlocking { ... } complete their execution. You will often see runBlocking used like that at the very top-level of the application and quite rarely inside the real code, as threads are expensive resources and blocking them is inefficient and is often not desired.
1> 런블록킹은 비용이 큰 일이며, 어플리케이션의 탑 레벨에서 주로 사용할 수 있으며, 코드 내부에서 사용하는 것은 자제해야한다.
Extract function refactoring
Let's extract the block of code inside launch { ... } into a separate function. When you perform "Extract function" refactoring on this code, you get a new function with the suspend modifier. This is your first suspending function. Suspending functions can be used inside coroutines just like regular functions, but their additional feature is that they can, in turn, use other suspending functions (like delay in this example) to suspend execution of a coroutine.
1> 서드펜드 함수는 코루틴 블록 내에서 동작하며 다른 서드펜드 함수를 사용할 수 있다.
fun main() = runBlocking { // this: CoroutineScope
launch { doWorld() }
println("Hello")
}
// this is your first suspending function
suspend fun doWorld() {
delay(1000L)
println("World!")
}
Scope builder
In addition to the coroutine scope provided by different builders, it is possible to declare your own scope using the coroutineScope builder.
It creates a coroutine scope and does not complete until all launched children complete.
runBlocking and coroutineScope builders may look similar because they both wait for their body and all its children to complete.
The main difference is that the runBlocking method blocks the current thread for waiting, while coroutineScope just suspends, releasing the underlying thread for other usages. Because of that difference, runBlocking is a regular function and coroutineScope is a suspending function.
You can use coroutineScope from any suspending function. For example, you can move the concurrent printing of Hello and World into a suspend fun doWorld() function:
fun main() = runBlocking {
doWorld()
}
suspend fun doWorld() = coroutineScope { // this: CoroutineScope
launch {
delay(1000L)
println("World!")
}
println("Hello")
}
1> runBlocking은 작업이 끝날때까지 현재 스레드를 blocking한다. 반면에, coroutineScope는 (다른 사용을 위해) 스레드를 blocking하지않고 단지 suspend만 한다.
2> 따라서 coroutineScope는 suspending Function의 어디에서 사용할 수 있다.
Scope builder and concurrency
A coroutineScope builder can be used inside any suspending function to perform multiple concurrent operations. Let's launch two concurrent coroutines inside a doWorld suspending function:
// Sequentially executes doWorld followed by "Done"
fun main() = runBlocking {
doWorld()
println("Done")
}
// Concurrently executes both sections
suspend fun doWorld() = coroutineScope { // this: CoroutineScope
launch {
delay(2000L)
println("World 2")
}
launch {
delay(1000L)
println("World 1")
}
println("Hello")
}
Both pieces of code inside launch { ... } blocks execute concurrently, with World 1 printed first, after a second from start, and World 2 printed next, after two seconds from start. A coroutineScope in doWorld completes only after both are complete, so doWorld returns and allows Done string to be printed only after that:
Hello
World 1
World 2
Done
1> coroutineScope안에서 launch 된 것은 동시에 실행된다. coroutineScope가 모두 끝나면 done출력된다.
An explicit job
A launch coroutine builder returns a Job object that is a handle to the launched coroutine and can be used to explicitly wait for its completion. For example, you can wait for completion of the child coroutine and then print "Done" string:
val job = launch { // launch a new coroutine and keep a reference to its Job
delay(1000L)
println("World!")
}
println("Hello")
job.join() // wait until child coroutine completes
println("Done")Hello
World!
Done1> launch block은 job을 리턴하며, 외부에서 이를 호출할 수 있다.
Coroutines ARE light-weight
Run the following code:
import kotlinx.coroutines.*
//sampleStart
fun main() = runBlocking {
repeat(100_000) { // launch a lot of coroutines
launch {
delay(5000L)
print(".")
}
}
}
//sampleEndIt launches 100K coroutines and, after 5 seconds, each coroutine prints a dot.
Now, try that with threads (remove runBlocking, replace launch with thread, and replace delay with Thread.sleep). What would happen? (Most likely your code will produce some sort of out-of-memory error)
1> 코루틴은 경량쓰레드이므로 다수의 코루틴 블록을 lauch해도 문제없다
2> Cancellation and timeouts
Cancelling coroutine execution
In a long-running application you might need fine-grained control on your background coroutines. For example, a user might have closed the page that launched a coroutine and now its result is no longer needed and its operation can be cancelled. The launch function returns a Job that can be used to cancel the running coroutine:
val job = launch {
repeat(1000) { i ->
println("job: I'm sleeping $i ...")
delay(500L)
}
}
delay(1300L) // delay a bit
println("main: I'm tired of waiting!")
job.cancel() // cancels the job
job.join() // waits for job's completion
println("main: Now I can quit.")It produces the following output:
job: I'm sleeping 0 ...
job: I'm sleeping 1 ...
job: I'm sleeping 2 ...
main: I'm tired of waiting!
main: Now I can quit.As soon as main invokes job.cancel, we don't see any output from the other coroutine because it was cancelled. There is also a Job extension function cancelAndJoin that combines cancel and join invocations.
1> cancel, join을 조합하여 코루틴을 취소할 수 있다.
Cancellation is cooperative
Coroutine cancellation is cooperative. A coroutine code has to cooperate to be cancellable. All the suspending functions in kotlinx.coroutines are cancellable. They check for cancellation of coroutine and throw CancellationException when cancelled. However, if a coroutine is working in a computation and does not check for cancellation, then it cannot be cancelled, like the following example shows:
val startTime = System.currentTimeMillis()
val job = launch(Dispatchers.Default) {
var nextPrintTime = startTime
var i = 0
while (i < 5) { // computation loop, just wastes CPU
// print a message twice a second
if (System.currentTimeMillis() >= nextPrintTime) {
println("job: I'm sleeping ${i++} ...")
nextPrintTime += 500L
}
}
}
delay(1300L) // delay a bit
println("main: I'm tired of waiting!")
job.cancelAndJoin() // cancels the job and waits for its completion
println("main: Now I can quit.")Run it to see that it continues to print "I'm sleeping" even after cancellation until the job completes by itself after five iterations.
1> computation loop에서는 취소할 수 없다
Making computation code cancellable
There are two approaches to making computation code cancellable. The first one is to periodically invoke a suspending function that checks for cancellation. There is a yield function that is a good choice for that purpose. The other one is to explicitly check the cancellation status. Let us try the latter approach.
Replace while (i < 5) in the previous example with while (isActive) and rerun it.
val startTime = System.currentTimeMillis()
val job = launch(Dispatchers.Default) {
var nextPrintTime = startTime
var i = 0
while (isActive) { // cancellable computation loop
// print a message twice a second
if (System.currentTimeMillis() >= nextPrintTime) {
println("job: I'm sleeping ${i++} ...")
nextPrintTime += 500L
}
}
}
delay(1300L) // delay a bit
println("main: I'm tired of waiting!")
job.cancelAndJoin() // cancels the job and waits for its completion
println("main: Now I can quit.")
isActive를 두고 coroutineScope에 개입하게 만들면 loop를 종료할 수 있다.
1> 주기적으로 suspending function의 cancellation을 체크하거나 explictly cancellation status를 체크하여 compuation code를 cancellation할 수 있다.
Closing resources with finally
Cancellable suspending functions throw CancellationException on cancellation which can be handled in the usual way. For example, try {...} finally {...} expression and Kotlin use function execute their finalization actions normally when a coroutine is cancelled:
val job = launch {
try {
repeat(1000) { i ->
println("job: I'm sleeping $i ...")
delay(500L)
}
} finally {
println("job: I'm running finally")
}
}
delay(1300L) // delay a bit
println("main: I'm tired of waiting!")
job.cancelAndJoin() // cancels the job and waits for its completion
println("main: Now I can quit.")Both join and cancelAndJoin wait for all finalization actions to complete, so the example above produces the following output:
job: I'm sleeping 0 ...
job: I'm sleeping 1 ...
job: I'm sleeping 2 ...
main: I'm tired of waiting!
job: I'm running finally
main: Now I can quit.
1> finalization을 사용할 수 있다
Run non-cancellable block
Any attempt to use a suspending function in the finally block of the previous example causes CancellationException, because the coroutine running this code is cancelled. Usually, this is not a problem, since all well-behaving closing operations (closing a file, cancelling a job, or closing any kind of a communication channel) are usually non-blocking and do not involve any suspending functions. However, in the rare case when you need to suspend in a cancelled coroutine you can wrap the corresponding code in withContext(NonCancellable) {...} using withContext function and NonCancellable context as the following example shows:
val job = launch {
try {
repeat(1000) { i ->
println("job: I'm sleeping $i ...")
delay(500L)
}
} finally {
withContext(NonCancellable) {
println("job: I'm running finally")
delay(1000L)
println("job: And I've just delayed for 1 sec because I'm non-cancellable")
}
}
}
delay(1300L) // delay a bit
println("main: I'm tired of waiting!")
job.cancelAndJoin() // cancels the job and waits for its completion
println("main: Now I can quit.")1> withContext(NonCancellable)를 사용하여 finally block에서 suspend function을 call할 수 있다
Timeout
The most obvious practical reason to cancel execution of a coroutine is because its execution time has exceeded some timeout. While you can manually track the reference to the corresponding Job and launch a separate coroutine to cancel the tracked one after delay, there is a ready to use withTimeout function that does it. Look at the following example:
withTimeout(1300L) {
repeat(1000) { i ->
println("I'm sleeping $i ...")
delay(500L)
}
}I'm sleeping 0 ...
I'm sleeping 1 ...
I'm sleeping 2 ...
Exception in thread "main" kotlinx.coroutines.TimeoutCancellationException: Timed out waiting for 1300 msThe TimeoutCancellationException that is thrown by withTimeout is a subclass of CancellationException. We have not seen its stack trace printed on the console before. That is because inside a cancelled coroutine CancellationException is considered to be a normal reason for coroutine completion. However, in this example we have used withTimeout right inside the main function.
Since cancellation is just an exception, all resources are closed in the usual way. You can wrap the code with timeout in a try {...} catch (e: TimeoutCancellationException) {...} block if you need to do some additional action specifically on any kind of timeout or use the withTimeoutOrNull function that is similar to withTimeout but returns null on timeout instead of throwing an exception:
val result = withTimeoutOrNull(1300L) {
repeat(1000) { i ->
println("I'm sleeping $i ...")
delay(500L)
}
"Done" // will get cancelled before it produces this result
}
println("Result is $result")I'm sleeping 0 ...
I'm sleeping 1 ...
I'm sleeping 2 ...
Result is null1> cacellation은 exception 이며, try catch로 감싸지 않으면 exception으로 빠지게 된다.
withTimeoutOrNull을 쓰면 예외로 빠지지 않게 할 수 있다
Asynchronous timeout and resources
The timeout event in withTimeout is asynchronous with respect to the code running in its block and may happen at any time, even right before the return from inside of the timeout block. Keep this in mind if you open or acquire some resource inside the block that needs closing or release outside of the block.
For example, here we imitate a closeable resource with the Resource class, that simply keeps track of how many times it was created by incrementing the acquired counter and decrementing this counter from its close function. Let us run a lot of coroutines with the small timeout try acquire this resource from inside of the withTimeout block after a bit of delay and release it from outside.
var acquired = 0
class Resource {
init { acquired++ } // Acquire the resource
fun close() { acquired-- } // Release the resource
}
fun main() {
runBlocking {
repeat(100_000) { // Launch 100K coroutines
launch {
val resource = withTimeout(60) { // Timeout of 60 ms
delay(50) // Delay for 50 ms
Resource() // Acquire a resource and return it from withTimeout block
}
resource.close() // Release the resource
}
}
}
// Outside of runBlocking all coroutines have completed
println(acquired) // Print the number of resources still acquired
}If you run the above code you'll see that it does not always print zero, though it may depend on the timings of your machine you may need to tweak timeouts in this example to actually see non-zero values.
위와 같이 구성하면 Resource에 접근하고 close하는데서 오는 시간차때문에 acquired가 0이 아닌 경우가 발생한다(이는 memory leak을 상정함)
이를 해결하기 위해서는 아래와같이 코드 구성을 하면된다.
runBlocking {
repeat(100_000) { // Launch 100K coroutines
launch {
var resource: Resource? = null // Not acquired yet
try {
withTimeout(60) { // Timeout of 60 ms
delay(50) // Delay for 50 ms
resource = Resource() // Store a resource to the variable if acquired
}
// We can do something else with the resource here
} finally {
resource?.close() // Release the resource if it was acquired
}
}
}
}
// Outside of runBlocking all coroutines have completed
println(acquired) // Print the number of resources still acquiredThis example always prints zero. Resources do not leak.
1> try-catch로 resource 접근에 대한 release를 정의하여 memory leak을 방지할 수 있다
3> Composing suspending functions
Sequential by default
Assume that we have two suspending functions defined elsewhere that do something useful like some kind of remote service call or computation. We just pretend they are useful, but actually each one just delays for a second for the purpose of this example:
suspend fun doSomethingUsefulOne(): Int {
delay(1000L) // pretend we are doing something useful here
return 13
}
suspend fun doSomethingUsefulTwo(): Int {
delay(1000L) // pretend we are doing something useful here, too
return 29
}What do we do if we need them to be invoked sequentially — first doSomethingUsefulOne and then doSomethingUsefulTwo, and compute the sum of their results? In practice, we do this if we use the result of the first function to make a decision on whether we need to invoke the second one or to decide on how to invoke it.
We use a normal sequential invocation, because the code in the coroutine, just like in the regular code, is sequential by default. The following example demonstrates it by measuring the total time it takes to execute both suspending functions:
위 두 메소드를 작업시 1초의 시간이 걸리는 유의미한 task라 생각하고 이 두 메소드를 어떻게 처리할지에 대한 고민이다.
먼저, 가장 단순하게, 직렬적으로 처리하면 아래와 같이 약 2초의 시간이 소요된다.
val time = measureTimeMillis {
val one = doSomethingUsefulOne()
val two = doSomethingUsefulTwo()
println("The answer is ${one + two}")
}
println("Completed in $time ms")The answer is 42
Completed in 2017 msConcurrent using async
What if there are no dependencies between invocations of doSomethingUsefulOne and doSomethingUsefulTwo and we want to get the answer faster, by doing both concurrently? This is where async comes to help.
Conceptually, async is just like launch. It starts a separate coroutine which is a light-weight thread that works concurrently with all the other coroutines. The difference is that launch returns a Job and does not carry any resulting value, while async returns a Deferred — a light-weight non-blocking future that represents a promise to provide a result later. You can use .await() on a deferred value to get its eventual result, but Deferred is also a Job, so you can cancel it if needed.
이를 좀더 빠르게 수행하기 위해서는 병렬적(concurrently)으로 수행하면되는데, 이때, 개념적으로 launch와 유사한 async라는 키워드를 사용한다.
async는 리턴이 job이 아니라 Deferred이며, 경량 논블로킹 퓨쳐인 이것은 결과값을 나중에 리턴할 것임을 약속(promise)한다. 따라서 deferred value에 .await()를 호출하면, result를 eventually 얻을 수 있게 된다. 또한 Deferred도 결국에는 Job이기에 cancel과 같은 메소드도 지원된다.
val time = measureTimeMillis {
val one = async { doSomethingUsefulOne() }
val two = async { doSomethingUsefulTwo() }
println("The answer is ${one.await() + two.await()}")
}
println("Completed in $time ms")The answer is 42
Completed in 1017 msThis is twice as fast, because the two coroutines execute concurrently. Note that concurrency with coroutines is always explicit.
Lazily started async
Optionally, async can be made lazy by setting its start parameter to CoroutineStart.LAZY. In this mode it only starts the coroutine when its result is required by await, or if its Job's start function is invoked. Run the following example:
val time = measureTimeMillis {
val one = async(start = CoroutineStart.LAZY) { doSomethingUsefulOne() }
val two = async(start = CoroutineStart.LAZY) { doSomethingUsefulTwo() }
// some computation
one.start() // start the first one
two.start() // start the second one
println("The answer is ${one.await() + two.await()}")
}
println("Completed in $time ms")The answer is 42
Completed in 1017 msSo, here the two coroutines are defined but not executed as in the previous example, but the control is given to the programmer on when exactly to start the execution by calling start. We first start one, then start two, and then await for the individual coroutines to finish.
Note that if we just call await in println without first calling start on individual coroutines, this will lead to sequential behavior, since await starts the coroutine execution and waits for its finish, which is not the intended use-case for laziness. The use-case for async(start = CoroutineStart.LAZY) is a replacement for the standard lazy function in cases when computation of the value involves suspending functions.
1> start / await 를 순차적으로 실행하여 async의 deferred를 순차적으로 실행할수 있으며, start없이 await를 해도 실행은 되지만 Laziness를 활용하라는 의도적인 동작 방식은 아님.
Async-style functions
We can define async-style functions that invoke doSomethingUsefulOne and doSomethingUsefulTwo asynchronously using the async coroutine builder using a GlobalScope reference to opt-out of the structured concurrency. We name such functions with the "...Async" suffix to highlight the fact that they only start asynchronous computation and one needs to use the resulting deferred value to get the result.
// The result type of somethingUsefulOneAsync is Deferred<Int>
@OptIn(DelicateCoroutinesApi::class)
fun somethingUsefulOneAsync() = GlobalScope.async {
doSomethingUsefulOne()
}
// The result type of somethingUsefulTwoAsync is Deferred<Int>
@OptIn(DelicateCoroutinesApi::class)
fun somethingUsefulTwoAsync() = GlobalScope.async {
doSomethingUsefulTwo()
}Note that these xxxAsync functions are notsuspending functions. They can be used from anywhere. However, their use always implies asynchronous (here meaning concurrent) execution of their action with the invoking code.
The following example shows their use outside of coroutine:
1> GlobalScope를 사용하여 notsuspend fuction의 result를 받아올 수 있다. 이때는 @OptIn annotation을 사용해야한다.
// note that we don't have `runBlocking` to the right of `main` in this example
fun main() {
val time = measureTimeMillis {
// we can initiate async actions outside of a coroutine
val one = somethingUsefulOneAsync()
val two = somethingUsefulTwoAsync()
// but waiting for a result must involve either suspending or blocking.
// here we use `runBlocking { ... }` to block the main thread while waiting for the result
runBlocking {
println("The answer is ${one.await() + two.await()}")
}
}
println("Completed in $time ms")
}위의 코드는 one, two가 coroutine block에서 작동하지않음을 확인할 수 있다.
그런데 위의 스타일은 설명을 위해 사용되며, 코틀린 코루틴의 스타일에서는 강력하게 권장하지 않는 스타일임
Consider what happens if between the val one = somethingUsefulOneAsync() line and one.await() expression there is some logic error in the code, and the program throws an exception, and the operation that was being performed by the program aborts. Normally, a global error-handler could catch this exception, log and report the error for developers, but the program could otherwise continue doing other operations. However, here we have somethingUsefulOneAsync still running in the background, even though the operation that initiated it was aborted. This problem does not happen with structured concurrency, as shown in the section below.
Structured concurrency with async
Let us take the Concurrent using async example and extract a function that concurrently performs doSomethingUsefulOne and doSomethingUsefulTwo and returns the sum of their results. Because the async coroutine builder is defined as an extension on CoroutineScope, we need to have it in the scope and that is what the coroutineScope function provides:
suspend fun concurrentSum(): Int = coroutineScope {
val one = async { doSomethingUsefulOne() }
val two = async { doSomethingUsefulTwo() }
one.await() + two.await()
}This way, if something goes wrong inside the code of the concurrentSum function, and it throws an exception, all the coroutines that were launched in its scope will be cancelled.
val time = measureTimeMillis {
println("The answer is ${concurrentSum()}")
}
println("Completed in $time ms")We still have concurrent execution of both operations, as evident from the output of the above main function:
The answer is 42
Completed in 1017 msCancellation is always propagated through coroutines hierarchy:
import kotlinx.coroutines.*
fun main() = runBlocking<Unit> {
try {
failedConcurrentSum()
} catch(e: ArithmeticException) {
println("Computation failed with ArithmeticException")
}
}
suspend fun failedConcurrentSum(): Int = coroutineScope {
val one = async<Int> {
try {
delay(Long.MAX_VALUE) // Emulates very long computation
42
} finally {
println("First child was cancelled")
}
}
val two = async<Int> {
println("Second child throws an exception")
throw ArithmeticException()
}
one.await() + two.await()
}Second child throws an exception
First child was cancelled
Computation failed with ArithmeticException1> "two"가 exception으로 빠지면 그 결과를 전파하여 "one"도 finally로 빠지게 만든뒤 코루틴을 종료하며 코루틴 전체를 감싼 try-catch에서 catch로 향하게 만든다.
4> Coroutine context and dispatchers
Coroutines always execute in some context represented by a value of the CoroutineContext type, defined in the Kotlin standard library.
The coroutine context is a set of various elements. The main elements are the Job of the coroutine, which we've seen before, and its dispatcher, which is covered in this section.
1> 코루틴은 항상 CoroutineContext 으로 표현된 context에서 실행됨
Dispatchers and threads
The coroutine context includes a coroutine dispatcher (see CoroutineDispatcher) that determines what thread or threads the corresponding coroutine uses for its execution. The coroutine dispatcher can confine coroutine execution to a specific thread, dispatch it to a thread pool, or let it run unconfined.
All coroutine builders like launch and async accept an optional CoroutineContext parameter that can be used to explicitly specify the dispatcher for the new coroutine and other context elements.
2> dispatcher 를 통해 명시적으로 코루틴 빌더에 대한 개입이 가능하다
Try the following example:
launch { // context of the parent, main runBlocking coroutine
println("main runBlocking : I'm working in thread ${Thread.currentThread().name}")
}
launch(Dispatchers.Unconfined) { // not confined -- will work with main thread
println("Unconfined : I'm working in thread ${Thread.currentThread().name}")
}
launch(Dispatchers.Default) { // will get dispatched to DefaultDispatcher
println("Default : I'm working in thread ${Thread.currentThread().name}")
}
launch(newSingleThreadContext("MyOwnThread")) { // will get its own new thread
println("newSingleThreadContext: I'm working in thread ${Thread.currentThread().name}")
}Unconfined : I'm working in thread main
Default : I'm working in thread DefaultDispatcher-worker-1
newSingleThreadContext: I'm working in thread MyOwnThread
main runBlocking : I'm working in thread mainWhen launch { ... } is used without parameters, it inherits the context (and thus dispatcher) from the CoroutineScope it is being launched from. In this case, it inherits the context of the main runBlocking coroutine which runs in the main thread.
Dispatchers.Unconfined is a special dispatcher that also appears to run in the main thread, but it is, in fact, a different mechanism that is explained later.
The default dispatcher is used when no other dispatcher is explicitly specified in the scope. It is represented by Dispatchers.Default and uses a shared background pool of threads.
newSingleThreadContext creates a thread for the coroutine to run. A dedicated thread is a very expensive resource. In a real application it must be either released, when no longer needed, using the close function, or stored in a top-level variable and reused throughout the application.
위와 같이 launch 블록에서 dispatcher를 정해주는것에 따라서 어떤 thread에서 동작시킬지를 정할 수 있다.
The unconfined dispatcher is an advanced mechanism that can be helpful in certain corner cases where dispatching of a coroutine for its execution later is not needed or produces undesirable side-effects, because some operation in a coroutine must be performed right away. The unconfined dispatcher should not be used in general code.
Children of a coroutine
When a coroutine is launched in the CoroutineScope of another coroutine, it inherits its context via CoroutineScope.coroutineContext and the Job of the new coroutine becomes a child of the parent coroutine's job. When the parent coroutine is cancelled, all its children are recursively cancelled, too.
However, this parent-child relation can be explicitly overriden in one of two ways:
- When a different scope is explicitly specified when launching a coroutine (for example, GlobalScope.launch), then it does not inherit a Job from the parent scope.
- When a different Job object is passed as the context for the new coroutine (as show in the example below), then it overrides the Job of the parent scope.
In both cases, the launched coroutine is not tied to the scope it was launched from and operates independently.
// launch a coroutine to process some kind of incoming request
val request = launch {
// it spawns two other jobs
launch(Job()) {
println("job1: I run in my own Job and execute independently!")
delay(1000)
println("job1: I am not affected by cancellation of the request")
}
// and the other inherits the parent context
launch {
delay(100)
println("job2: I am a child of the request coroutine")
delay(1000)
println("job2: I will not execute this line if my parent request is cancelled")
}
}
delay(500)
request.cancel() // cancel processing of the request
delay(1000) // delay a second to see what happens
println("main: Who has survived request cancellation?")job1: I run in my own Job and execute independently!
job2: I am a child of the request coroutine
job1: I am not affected by cancellation of the request
main: Who has survived request cancellation?request.cancel을 호출하면 job2의 1100 이후 동작하는 요소는 cancel된다.
Parental responsibilities
A parent coroutine always waits for completion of all its children. A parent does not have to explicitly track all the children it launches, and it does not have to use Job.join to wait for them at the end:
// launch a coroutine to process some kind of incoming request
val request = launch {
repeat(3) { i -> // launch a few children jobs
launch {
delay((i + 1) * 200L) // variable delay 200ms, 400ms, 600ms
println("Coroutine $i is done")
}
}
println("request: I'm done and I don't explicitly join my children that are still active")
}
request.join() // wait for completion of the request, including all its children
println("Now processing of the request is complete")request: I'm done and I don't explicitly join my children that are still active
Coroutine 0 is done
Coroutine 1 is done
Coroutine 2 is done
Now processing of the request is complete
1> 자식 코루틴에 대한 join을 호출할 필요없이 부모 코루틴은 자식의 completion을 기다림
Naming coroutines for debugging
Automatically assigned ids are good when coroutines log often and you just need to correlate log records coming from the same coroutine. However, when a coroutine is tied to the processing of a specific request or doing some specific background task, it is better to name it explicitly for debugging purposes. The CoroutineName context element serves the same purpose as the thread name. It is included in the thread name that is executing this coroutine when the debugging mode is turned on.
The following example demonstrates this concept:
코루틴에 명시적 이름을 달아 디버깅에 도움을 줄 수 있다
log("Started main coroutine")
// run two background value computations
val v1 = async(CoroutineName("v1coroutine")) {
delay(500)
log("Computing v1")
252
}
val v2 = async(CoroutineName("v2coroutine")) {
delay(1000)
log("Computing v2")
6
}
log("The answer for v1 / v2 = ${v1.await() / v2.await()}")
The output it produces with -Dkotlinx.coroutines.debug JVM option is similar to:
[main @main#1] Started main coroutine
[main @v1coroutine#2] Computing v1
[main @v2coroutine#3] Computing v2
[main @main#1] The answer for v1 / v2 = 42
(이후 dispatchers 파트는 덜 중요한 것같아 생략함)
참고 : https://kotlinlang.org/docs/coroutine-context-and-dispatchers.html#coroutine-scope
5> Asynchronous Flow
A suspending function asynchronously returns a single value, but how can we return multiple asynchronously computed values? This is where Kotlin Flows come in.
1> suspending function은 단일 value를 리턴하지만, multiple asynchrously computed value를 리턴하기 위해서는 Kotlin Flow를 사용해야한다!! (이것이 핵심 키워드이며 반드시 기억하자)
Representing multiple values
Multiple values can be represented in Kotlin using collections. For example, we can have a simple function that returns a List of three numbers and then print them all using forEach:
fun simple(): List<Int> = listOf(1, 2, 3)
fun main() {
simple().forEach { value -> println(value) }
}This code outputs:
1
2
3Sequences
If we are computing the numbers with some CPU-consuming blocking code (each computation taking 100ms), then we can represent the numbers using a Sequence:
fun simple(): Sequence<Int> = sequence { // sequence builder
for (i in 1..3) {
Thread.sleep(100) // pretend we are computing it
yield(i) // yield next value
}
}
fun main() {
simple().forEach { value -> println(value) }
}This code outputs the same numbers, but it waits 100ms before printing each one.
2> blocking code를 계산하려면 Sequence를 쓴다
Suspending functions
However, this computation blocks the main thread that is running the code. When these values are computed by asynchronous code we can mark the simple function with a suspend modifier, so that it can perform its work without blocking and return the result as a list:
sequence는 main thread를 blocking 하므로, blocking 없이 비동기로 작업을 수행하기위해 suspend function을 사용하자
suspend fun simple(): List<Int> {
delay(1000) // pretend we are doing something asynchronous here
return listOf(1, 2, 3)
}
fun main() = runBlocking<Unit> {
simple().forEach { value -> println(value) }
}This code prints the numbers after waiting for a second.
Flows
Using the List<Int> result type, means we can only return all the values at once. To represent the stream of values that are being asynchronously computed, we can use a Flow<Int> type just like we would use the Sequence<Int> type for synchronously computed values:
List<Int> 타입은 한번에 모든 값을 리턴한다. 비동기로 계산되는 stream 값을 표현하려면 Flow<Int> 타입을 사용하라.
fun simple(): Flow<Int> = flow { // flow builder
for (i in 1..3) {
delay(100) // pretend we are doing something useful here
emit(i) // emit next value
}
}
fun main() = runBlocking<Unit> {
// Launch a concurrent coroutine to check if the main thread is blocked
launch {
for (k in 1..3) {
println("I'm not blocked $k")
delay(100)
}
}
// Collect the flow
simple().collect { value -> println(value) }
}I'm not blocked 1
1
I'm not blocked 2
2
I'm not blocked 3
3This code waits 100ms before printing each number without blocking the main thread. This is verified by printing "I'm not blocked" every 100ms from a separate coroutine that is running in the main thread
위 코드는 메인스레드의 블로킹 없이 각각의 수를 프린팅하기전에 100ms를 기다린다.
Notice the following differences in the code with the Flow from the earlier examples:
- A builder function for Flow type is called flow.
- Code inside the flow { ... } builder block can suspend.
- The simple function is no longer marked with suspend modifier.
- Values are emitted from the flow using emit function.
- Values are collected from the flow using collect function.
앞선 방법과의 차이점은,
1. flow { }는 suspend block
2. suspend modifer mark가 필요없음
3. value는 emit function로 emitting함
4. collect 메소드로 flow로부터 오는 값을 collect한다.
는 것이다.
We can replace delay with Thread.sleep in the body of simple's flow { ... } and see that the main thread is blocked in this case.
Flows are cold
플로우는 Cold임
Flows are cold streams similar to sequences — the code inside a flow builder does not run until the flow is collected. This becomes clear in the following example:
flow가 collected 되기전까지 flow builder는 run 하지 않는다.
fun simple(): Flow<Int> = flow {
println("Flow started")
for (i in 1..3) {
delay(100)
emit(i)
}
}
fun main() = runBlocking<Unit> {
println("Calling simple function...")
val flow = simple()
println("Calling collect...")
flow.collect { value -> println(value) }
println("Calling collect again...")
flow.collect { value -> println( "result : "+ value) }
}
Calling simple function...
Calling collect...
Flow started
1
2
3
Calling collect again...
Flow started
result : 1
result : 2
result : 3This is a key reason the simple function (which returns a flow) is not marked with suspend modifier. By itself, simple() call returns quickly and does not wait for anything. The flow starts every time it is collected, that is why we see "Flow started" when we call collect again.
cold function이기에 suspend modifier라는 마크가 붙지 않는다.
simple 함수 자체가 not wait for anything 이며, collect를 시작할때 flow가 시작하게 된다.
collect를 할때마다 simple()에서 값을 받아오기때문에 Flow started라는 메세지를 2번 보게됨을 유의하자.
Flow cancellation basics
Flow adheres to the general cooperative cancellation of coroutines. As usual, flow collection can be cancelled when the flow is suspended in a cancellable suspending function (like delay). The following example shows how the flow gets cancelled on a timeout when running in a withTimeoutOrNull block and stops executing its code:
fun simple(): Flow<Int> = flow {
for (i in 1..3) {
delay(100)
println("Emitting $i")
emit(i)
}
}
fun main() = runBlocking<Unit> {
withTimeoutOrNull(250) { // Timeout after 250ms
simple().collect { value -> println(value) }
}
println("Done")
}Emitting 1
1
Emitting 2
2
Done
기존의 코루틴처럼 cancellation을 위 예제처럼 적용할 수 있다
Flow builders
The flow { ... } builder from the previous examples is the most basic one. There are other builders for easier declaration of flows:
- flowOf builder that defines a flow emitting a fixed set of values.
- Various collections and sequences can be converted to flows using .asFlow() extension functions.
flow{ } 를 사용하는 것은 가장 기본적인 방법이며, 다른 방법으로 flow builder를 사용하는 방법은 다음과 같다
flowOf사용, 혹은 asFlow()로 flow 변환
// Convert an integer range to a flow
(1..3).asFlow().collect { value -> println(value) }1
2
3Intermediate flow operators
Flows can be transformed with operators, just as you would with collections and sequences. Intermediate operators are applied to an upstream flow and return a downstream flow. These operators are cold, just like flows are. A call to such an operator is not a suspending function itself. It works quickly, returning the definition of a new transformed flow.
The basic operators have familiar names like map and filter. The important difference to sequences is that blocks of code inside these operators can call suspending functions.
For example, a flow of incoming requests can be mapped to the results with the map operator, even when performing a request is a long-running operation that is implemented by a suspending function:
flow operator로 upstream에서 온 flow를 처리하여 downstream으로 전달할 수 있다
basic operator map, fliter같은 애들은 suspending function을 call할 수 있다.
suspend fun performRequest(request: Int): String {
delay(1000) // imitate long-running asynchronous work
return "response $request"
}
fun main() = runBlocking<Unit> {
(1..3).asFlow() // a flow of requests
.map { request -> performRequest(request) }
.collect { response -> println(response) }
}It produces the following three lines, each line appearing after each second:
response 1
response 2
response 3Transform operator
Among the flow transformation operators, the most general one is called transform. It can be used to imitate simple transformations like map and filter, as well as implement more complex transformations. Using the transform operator, we can emit arbitrary values an arbitrary number of times.
For example, using transform we can emit a string before performing a long-running asynchronous request and follow it with a response:
(1..3).asFlow() // a flow of requests
.transform { request ->
emit("Making request $request")
emit(performRequest(request))
}
.collect { response -> println(response) }Making request 1
response 1
Making request 2
response 2
Making request 3
response 3
transform operator를 사용하여 emit을 더하거나 변형하는 등의 다양한 형태로 flow를 transforming 할 수 있다
Size-limiting operators
Size-limiting intermediate operators like take cancel the execution of the flow when the corresponding limit is reached. Cancellation in coroutines is always performed by throwing an exception, so that all the resource-management functions (like try { ... } finally { ... } blocks) operate normally in case of cancellation:
fun numbers(): Flow<Int> = flow {
try {
emit(1)
emit(2)
println("This line will not execute")
emit(3)
} finally {
println("Finally in numbers")
}
}
fun main() = runBlocking<Unit> {
numbers()
.take(2) // take only the first two
.collect { value -> println(value) }
}take operator는 flow execution을 limit이 도달했을 때, cancel할 수 있다.
cancellation은 always performing throwing the exception 이므로 resource-management function like try { } finally {} 로 처리를 해주어야한다.
The output of this code clearly shows that the execution of the flow { ... } body in the numbers() function stopped after emitting the second number:
1
2
Finally in numbers
Terminal flow operators
Terminal operators on flows are suspending functions that start a collection of the flow. The collect operator is the most basic one, but there are other terminal operators, which can make it easier:
터미널 오퍼레이터는 flow의 데이터 스트림을 처리하는 최종단에서 suspending functions로 동작하는 부분에 대한 처리를 담당한다.
먼저, collect라는 operator가 가장 기본적인 terminal operator로써 존재하고 toList, toSet등의 다양한 terminal operator를 사용하여 flow를 처리할 수 있다
- Conversion to various collections like toList and toSet.
- Operators to get the first value and to ensure that a flow emits a single value.
- Reducing a flow to a value with reduce and fold.
For example:
val sum = (1..5).asFlow()
.map { it * it } // squares of numbers from 1 to 5
.reduce { a, b -> a + b } // sum them (terminal operator)
println(sum)Prints a single number:
55
reduce, fold와 같은 operator도 지원한다.
추가 예제(2022.10.30) : 아래의 terminal operator(collect와 toList)를 확인해보자
1. collect를 사용한 예제
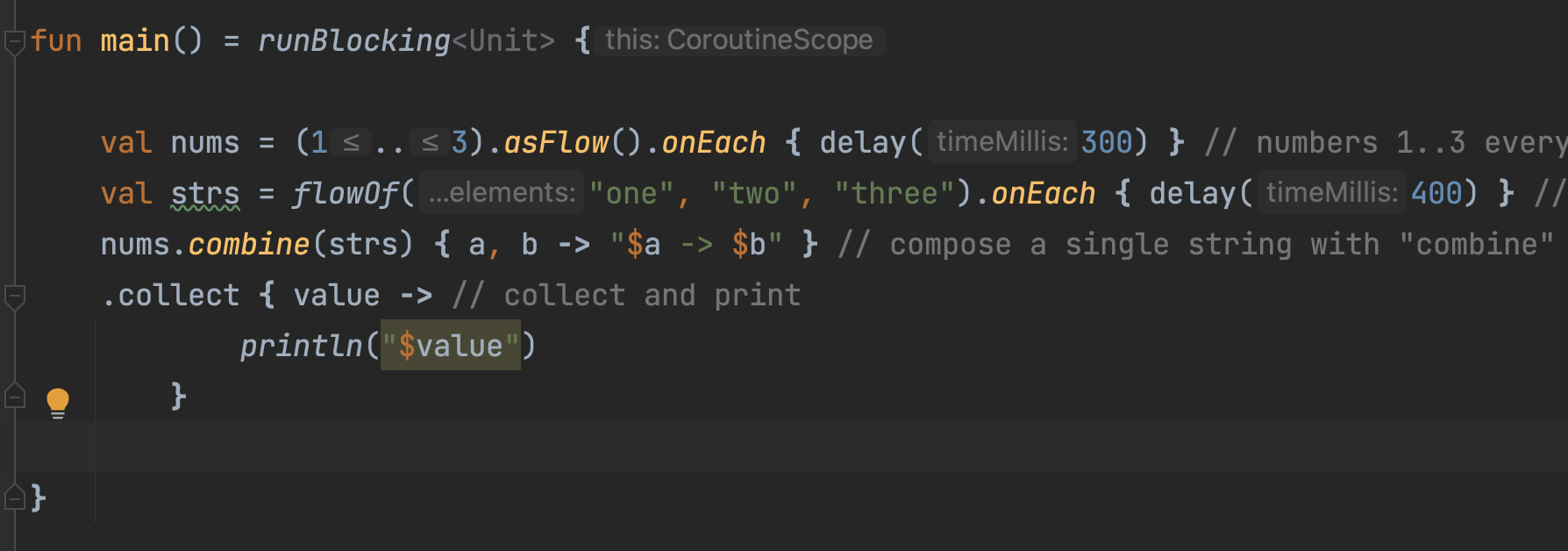

2. toList를 사용한 예제


Flows are sequential
Each individual collection of a flow is performed sequentially unless special operators that operate on multiple flows are used. The collection works directly in the coroutine that calls a terminal operator. No new coroutines are launched by default. Each emitted value is processed by all the intermediate operators from upstream to downstream and is then delivered to the terminal operator after.
See the following example that filters the even integers and maps them to strings:
구글 번역 : 여러 흐름에서 작동하는 특수 연산자를 사용하지 않는 한 흐름의 각 개별 컬렉션은 순차적으로 수행됩니다. 컬렉션은 터미널 연산자를 호출하는 코루틴에서 직접 작동합니다. 기본적으로 새로운 코루틴이 실행되지 않습니다. 각 방출 값은 업스트림에서 다운스트림으로 모든 중간 운영자에 의해 처리된 후 터미널 운영자에게 전달됩니다.
즉, collection의 deafult operating은 sequential 이며, basically, new coroutine is not defined by basic operator라는 의미이다.
See the following example that filters the even integers and maps them to strings:
(1..5).asFlow()
.filter {
println("Filter $it")
it % 2 == 0
}
.map {
println("Map $it")
"string $it"
}.collect {
println("Collect $it")
}
위 코드는 1,2,3,4,5가 순차적으로 들어가서 collect시 모든 값이 일시에 방출되는 것이 아닌 순차적으로 operator를 따라서 sequentially 동작하는 것을 보여주는 예제이다.
Producing:
Filter 1
Filter 2
Map 2
Collect string 2
Filter 3
Filter 4
Map 4
Collect string 4
Filter 5Flow context
Collection of a flow always happens in the context of the calling coroutine. For example, if there is a simple flow, then the following code runs in the context specified by the author of this code, regardless of the implementation details of the simple flow:
withContext(context) {
simple().collect { value ->
println(value) // run in the specified context
}
}So, by default, code in the flow { ... } builder runs in the context that is provided by a collector of the corresponding flow. For example, consider the implementation of a simple function that prints the thread it is called on and emits three numbers:
fun simple(): Flow<Int> = flow {
log("Started simple flow")
for (i in 1..3) {
emit(i)
}
}
fun main() = runBlocking<Unit> {
simple().collect { value -> log("Collected $value") }
}Running this code produces:
[main @coroutine#1] Started simple flow
[main @coroutine#1] Collected 1
[main @coroutine#1] Collected 2
[main @coroutine#1] Collected 3Since simple().collect is called from the main thread, the body of simple's flow is also called in the main thread. This is the perfect default for fast-running or asynchronous code that does not care about the execution context and does not block the caller.
실행 코드에 블로킹 되지않고 비동기적으로 simple()이 collect된다
Wrong emission withContext
However, the long-running CPU-consuming code might need to be executed in the context of Dispatchers.Default and UI-updating code might need to be executed in the context of Dispatchers.Main. Usually, withContext is used to change the context in the code using Kotlin coroutines, but code in the flow { ... } builder has to honor the context preservation property and is not allowed to emit from a different context.
CPU-consuming 하는 장기간 실행되는 코드는 Dispather.Default에서 실행
UI update code는 Dispatcher.Main에서 실행한다.
대개 withContext는 코틀린 코루틴을 사용해서 context를 변경하는데 사용하지만 flow { } builder는 context 보존 속성을 준수해야되며, 다른 컨텍스트에 emit하는 것을 허용하지 않는c다.
fun simple(): Flow<Int> = flow {
// The WRONG way to change context for CPU-consuming code in flow builder
kotlinx.coroutines.withContext(Dispatchers.Default) {
for (i in 1..3) {
Thread.sleep(100) // pretend we are computing it in CPU-consuming way
emit(i) // emit next value
}
}
}
fun main() = runBlocking<Unit> {
simple().collect { value -> println(value) }
}Exception in thread "main" java.lang.IllegalStateException: Flow invariant is violated:
Flow was collected in [CoroutineId(1), "coroutine#1":BlockingCoroutine{Active}@5511c7f8, BlockingEventLoop@2eac3323],
but emission happened in [CoroutineId(1), "coroutine#1":DispatchedCoroutine{Active}@2dae0000, Dispatchers.Default].
Please refer to 'flow' documentation or use 'flowOn' instead
와 같은 예외가 발생한다.
flowOn operator
The exception refers to the flowOn function that shall be used to change the context of the flow emission. The correct way to change the context of a flow is shown in the example below, which also prints the names of the corresponding threads to show how it all works:
flow emission의 context를 바꾸기 위한 방법으로는 flowOn이 사용됨
fun simple(): Flow<Int> = flow {
for (i in 1..3) {
Thread.sleep(100) // pretend we are computing it in CPU-consuming way
log("Emitting $i")
emit(i) // emit next value
}
}.flowOn(Dispatchers.Default) // RIGHT way to change context for CPU-consuming code in flow builder
fun main() = runBlocking<Unit> {
simple().collect { value ->
log("Collected $value")
}
}[DefaultDispatcher-worker-1 @coroutine#2] Emitting 1
[main @coroutine#1] Collected 1
[DefaultDispatcher-worker-1 @coroutine#2] Emitting 2
[main @coroutine#1] Collected 2
[DefaultDispatcher-worker-1 @coroutine#2] Emitting 3
[main @coroutine#1] Collected 3Notice how flow { ... } works in the background thread, while collection happens in the main thread:
Another thing to observe here is that the flowOn operator has changed the default sequential nature of the flow. Now collection happens in one coroutine ("coroutine#1") and emission happens in another coroutine ("coroutine#2") that is running in another thread concurrently with the collecting coroutine. The flowOn operator creates another coroutine for an upstream flow when it has to change the CoroutineDispatcher in its context.
flow { } 는 background thread에서 동작하며, collection은 main thread에서 동작한다.
flowerOn은 default sequential nature of the flow를 바꾼다.
.flowOn이 없다면 아래와 같은 결과값, 즉 emit 되고, collect되는 coroutine 위치가 동일하다.
[main @coroutine#1] Emitting 1
[main @coroutine#1] Collected 1
[main @coroutine#1] Emitting 2
[main @coroutine#1] Collected 2
[main @coroutine#1] Emitting 3
[main @coroutine#1] Collected 3flowOn은 upStream flow를 위한 또다른 coroutine을 생성하여 CoroutineDispatcher를 바꿔주는 역할을 한다.
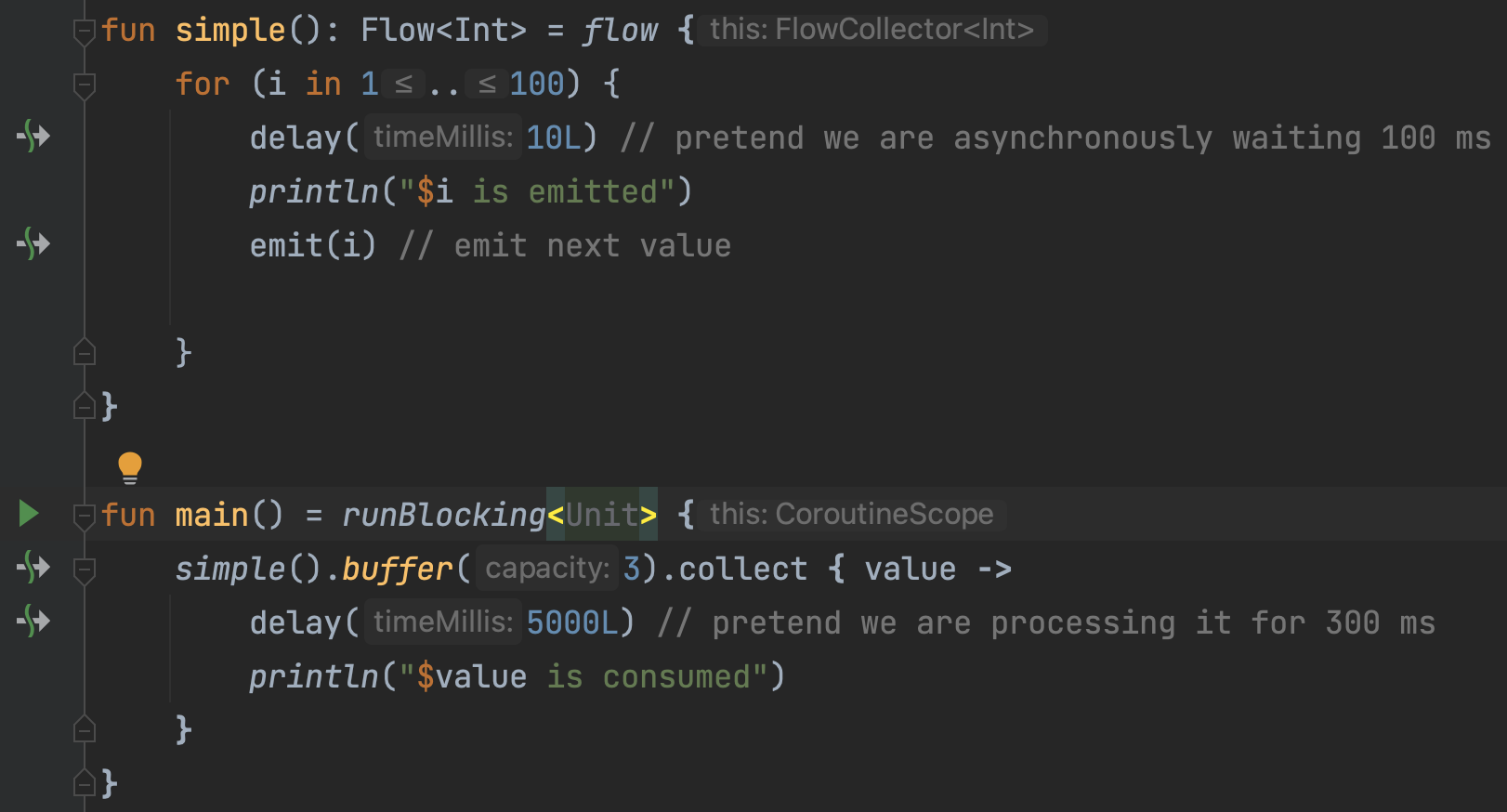
Buffering
Running different parts of a flow in different coroutines can be helpful from the standpoint of the overall time it takes to collect the flow, especially when long-running asynchronous operations are involved. For example, consider a case when the emission by a simple flow is slow, taking 100 ms to produce an element; and collector is also slow, taking 300 ms to process an element. Let's see how long it takes to collect such a flow with three numbers:
실행시 flow의 여러 부분에서 여러 개의 코루틴을 사용하는 것은 성능개선에 도움이 될 수 있다.
아래 코드를 확인하자.
fun simple(): Flow<Int> = flow {
for (i in 1..3) {
delay(100) // pretend we are asynchronously waiting 100 ms
emit(i) // emit next value
}
}
fun main() = runBlocking<Unit> {
val time = measureTimeMillis {
simple().collect { value ->
delay(300) // pretend we are processing it for 300 ms
println(value)
}
}
println("Collected in $time ms")
}It produces something like this, with the whole collection taking around 1200 ms (three numbers, 400 ms for each):
1
2
3
Collected in 1220 ms1,2,3 발행시 각각 100ms, collect후 발행시 각각의 elements에 300ms가 걸리므로, 100*3 + 300*3 = 1200이 소요된다.
We can use a buffer operator on a flow to run emitting code of the simple flow concurrently with collecting code, as opposed to running them sequentially:
val time = measureTimeMillis {
simple()
.buffer() // buffer emissions, don't wait
.collect { value ->
delay(300) // pretend we are processing it for 300 ms
println(value)
}
}
println("Collected in $time ms")위와 같이 buffer를 사용한다면, 발행되는 1,2,3에 각각의 코루틴을 생성하여 딜레이를 줄일 수 있다.
It produces the same numbers just faster, as we have effectively created a processing pipeline, having to only wait 100 ms for the first number and then spending only 300 ms to process each number. This way it takes around 1000 ms to run:
1
2
3
Collected in 1071 msNote that the flowOn operator uses the same buffering mechanism when it has to change a CoroutineDispatcher, but here we explicitly request buffering without changing the execution context.
2022-10-29) 보충 : Buffer는 Consumer에 Emitting 되는 쪽과는 다른 Coroutine을 사용함으로써 딜레이를 줄인다는 것이 핵심이다(참고한 블로그 : https://kotlinworld.com/252?category=973477).
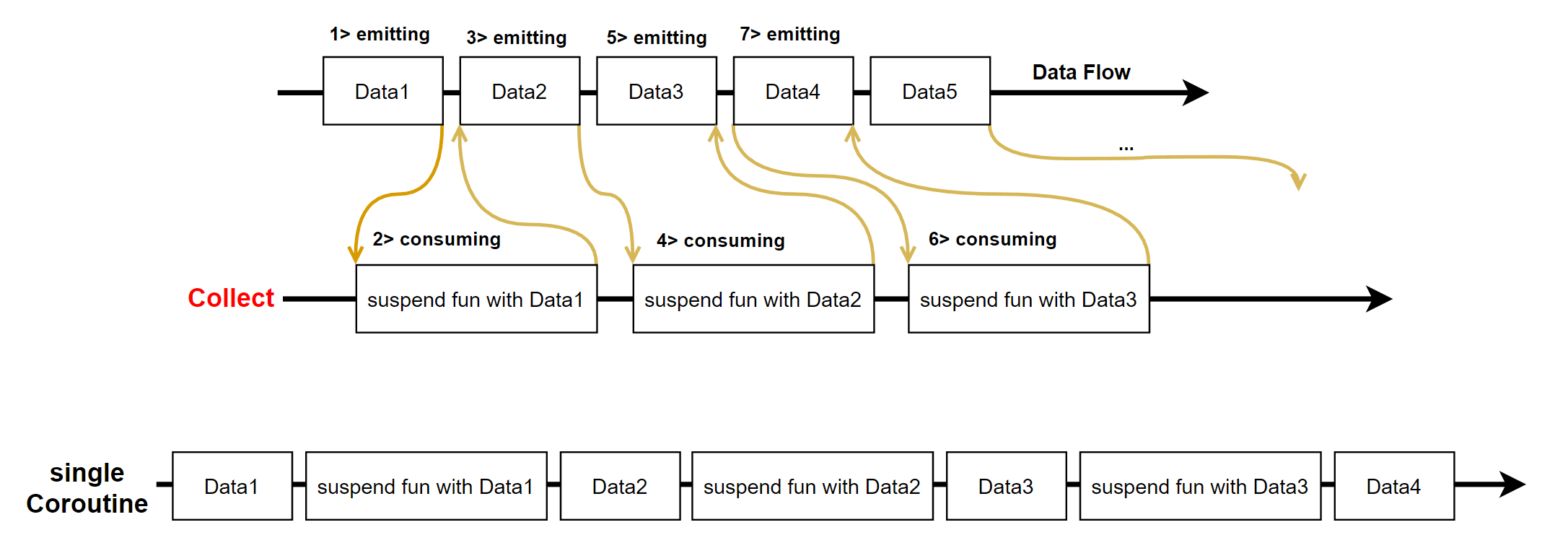
Buffer Capacity를 3으로 두고 실행하였을때 5개가 먼저 실행된 뒤 Consuming을 위해 대기하는 것을 아래의 코드에서 확인할 수 있다( 왜 Buffer Size + 2인지는...?? Capacity = 0 일때는 버퍼가 없는 것과 같은 동작을 하게 된다)

Conflation
When a flow represents partial results of the operation or operation status updates, it may not be necessary to process each value, but instead, only most recent ones. In this case, the conflate operator can be used to skip intermediate values when a collector is too slow to process them. Building on the previous example:
val time = measureTimeMillis {
simple()
.conflate() // conflate emissions, don't process each one
.collect { value ->
delay(300) // pretend we are processing it for 300 ms
println(value)
}
}
println("Collected in $time ms")We see that while the first number was still being processed the second, and third were already produced, so the second one was conflated and only the most recent (the third one) was delivered to the collector:
1
3
Collected in 758 ms융합, conflation은 intermediate value를 skip하고 최근의 값을 반환한다.
simple이 100ms 당 한개씩 반환하므로, 1이 처리 되고 있을때(300ms) 2,3이 이미 처리되었다, println을 하려고 보니 collect는 3이 가장 최근 값이므로, 3이 반환된다.
2022-10-29) 보충 :
produce한 대상을 collect가 소비할때 data pipe는 parallelly 동작하며, 대상 data의 consume이 온전히 끝났을 때, producing 된 데이터 중 most recently한 것을 collecting하여 consuming한다.
Buffer와 같이 Emitting과 Collecting 에 대한 Coroutine이 개별 동작한다.

Processing the latest value
Conflation is one way to speed up processing when both the emitter and collector are slow. It does it by dropping emitted values. The other way is to cancel a slow collector and restart it every time a new value is emitted. There is a family of xxxLatest operators that perform the same essential logic of a xxx operator, but cancel the code in their block on a new value. Let's try changing conflate to collectLatest in the previous example:
val time = measureTimeMillis {
simple()
.collectLatest { value -> // cancel & restart on the latest value
println("Collecting $value")
delay(300) // pretend we are processing it for 300 ms
println("Done $value")
}
}
println("Collected in $time ms")collectLastest를 사용하면 slow Collector를 cancel하고 새 collector가 new value emit를 수집한다.
Since the body of collectLatest takes 300 ms, but new values are emitted every 100 ms, we see that the block is run on every value, but completes only for the last value:

Collecting 1
Collecting 2
Collecting 3
Done 3
Collected in 741 ms
2022-10-29) 보충 : 단순 collect를 사용하는 것은 UI 처리와 같은 부분에 있어 한계가 있을 수 있다(https://kotlinworld.com/252?category=973477). 그 한계는 collect하는 부분에서의 processing delay에 의해 producing하는 부분과의 처리 속도 차이에 의한 원인이 대표적이다. 이를 극복하는 대안으로 collectLast를 사용한다. collectLast는 producing data가 생겼을 때 consuming부분에서 기존 data의 processing을 중단하고, producing된 data를 사용하여 새로 consuming을 시작하는 방법이다. 이에 대한 한계점은 processing 하는 시간이 producing하는 시간보다 일관적으로 크게 될 경우, 중간에 발행된 데이터들에 대한 처리는 누락될 가능성이 높다는 것이다.

Composing multiple flows
There are lots of ways to compose multiple flows.
Zip
Just like the Sequence.zip extension function in the Kotlin standard library, flows have a zip operator that combines the corresponding values of two flows:
val nums = (1..3).asFlow() // numbers 1..3
val strs = flowOf("one", "two", "three") // strings
nums.zip(strs) { a, b -> "$a -> $b" } // compose a single string
.collect { println(it) } // collect and printThis example prints:
1 -> one
2 -> two
3 -> threeCombine
When flow represents the most recent value of a variable or operation (see also the related section on conflation), it might be needed to perform a computation that depends on the most recent values of the corresponding flows and to recompute it whenever any of the upstream flows emit a value. The corresponding family of operators is called combine.
upstream에서 emit 된 값이 있을때마다 recompute를 수행하는 역할을 할 때, combine을 사용하여 구성할 수 있다.
For example, if the numbers in the previous example update every 300ms, but strings update every 400 ms, then zipping them using the zip operator will still produce the same result, albeit results that are printed every 400 ms:
We use a onEach intermediate operator in this example to delay each element and make the code that emits sample flows more declarative and shorter.
val nums = (1..3).asFlow().onEach { delay(300) } // numbers 1..3 every 300 ms
val strs = flowOf("one", "two", "three").onEach { delay(400) } // strings every 400 ms
val startTime = System.currentTimeMillis() // remember the start time
nums.zip(strs) { a, b -> "$a -> $b" } // compose a single string with "zip"
.collect { value -> // collect and print
println("$value at ${System.currentTimeMillis() - startTime} ms from start")
}nums와 stars가 emit될때 delay가 다른 문제에 의해 collect할때 start 시점은 다음과 같다
1 -> one at 449 ms from start
2 -> two at 849 ms from start
3 -> three at 1251 ms from startcombine을 쓰게 되면, 양쪽의 값중 어느하나가 업데이트 될때마다 collecting된다.
val nums = (1..3).asFlow().onEach { delay(300) } // numbers 1..3 every 300 ms
val strs = flowOf("one", "two", "three").onEach { delay(400) } // strings every 400 ms
val startTime = System.currentTimeMillis() // remember the start time
nums.combine(strs) { a, b -> "$a -> $b" } // compose a single string with "combine"
.collect { value -> // collect and print
println("$value at ${System.currentTimeMillis() - startTime} ms from start")
}1 -> one at 441 ms from start
2 -> one at 643 ms from start
2 -> two at 843 ms from start
3 -> two at 944 ms from start
3 -> three at 1243 ms from start1, one
2, one
2, two
... 와 같은 순서로 collect된다.
Flattening flows
Flows represent asynchronously received sequences of values, so it is quite easy to get in a situation where each value triggers a request for another sequence of values. For example, we can have the following function that returns a flow of two strings 500 ms apart:
fun requestFlow(i: Int): Flow<String> = flow {
emit("$i: First")
delay(500) // wait 500 ms
emit("$i: Second")
}Now if we have a flow of three integers and call requestFlow for each of them like this:
(1..3).asFlow().map { requestFlow(it) }Then we end up with a flow of flows (Flow<Flow<String>>) that needs to be flattened into a single flow for further processing. Collections and sequences have flatten and flatMap operators for this. However, due to the asynchronous nature of flows they call for different modes of flattening, as such, there is a family of flattening operators on flows.
위를 전개하면 flow < flow < string > > 이 되므로 flatten이나 flatMap으로 처리하면 유용할 때가 생긴다.
flatMapConcat
Concatenating mode is implemented by flatMapConcat and flattenConcat operators. They are the most direct analogues of the corresponding sequence operators. They wait for the inner flow to complete before starting to collect the next one as the following example shows:
val startTime = System.currentTimeMillis() // remember the start time
(1..3).asFlow().onEach { delay(100) } // a number every 100 ms
.flatMapConcat { requestFlow(it) }
.collect { value -> // collect and print
println("$value at ${System.currentTimeMillis() - startTime} ms from start")
}도식화 해보면 아래와 같다

위의 값이 각각 딜레이를 가지고 출력되면 아래와 같음
1: First at 121 ms from start
1: Second at 622 ms from start
2: First at 727 ms from start
2: Second at 1227 ms from start
3: First at 1328 ms from start
3: Second at 1829 ms from startflatMapMerge
Another flattening mode is to concurrently collect all the incoming flows and merge their values into a single flow so that values are emitted as soon as possible. It is implemented by flatMapMerge and flattenMerge operators. They both accept an optional concurrency parameter that limits the number of concurrent flows that are collected at the same time (it is equal to DEFAULT_CONCURRENCY by default).
val startTime = System.currentTimeMillis() // remember the start time
(1..3).asFlow().onEach { delay(100) } // a number every 100 ms
.flatMapMerge { requestFlow(it) }
.collect { value -> // collect and print
println("$value at ${System.currentTimeMillis() - startTime} ms from start")
}
도식화 해보면 아래와 같다

위의 값이 각각 딜레이를 가지고 출력되면 아래와 같음
The concurrent nature of flatMapMerge is obvious:
1: First at 136 ms from start
2: First at 231 ms from start
3: First at 333 ms from start
1: Second at 639 ms from start
2: Second at 732 ms from start
3: Second at 833 ms from startNote that the flatMapMerge calls its block of code ({ requestFlow(it) } in this example) sequentially, but collects the resulting flows concurrently, it is the equivalent of performing a sequential map { requestFlow(it) } first and then calling flattenMerge on the result.
flatMapLatest
In a similar way to the collectLatest operator, that was shown in "Processing the latest value" section, there is the corresponding "Latest" flattening mode where a collection of the previous flow is cancelled as soon as new flow is emitted. It is implemented by the flatMapLatest operator.
val startTime = System.currentTimeMillis() // remember the start time
(1..3).asFlow().onEach { delay(100) } // a number every 100 ms
.flatMapLatest { requestFlow(it) }
.collect { value -> // collect and print
println("$value at ${System.currentTimeMillis() - startTime} ms from start")
}flow에 최신 데이터가 들어오면 기존의 flow는 cancel 되고 최신의 데이터에 의한 flow가 새로 만들어지며 collect 된다.
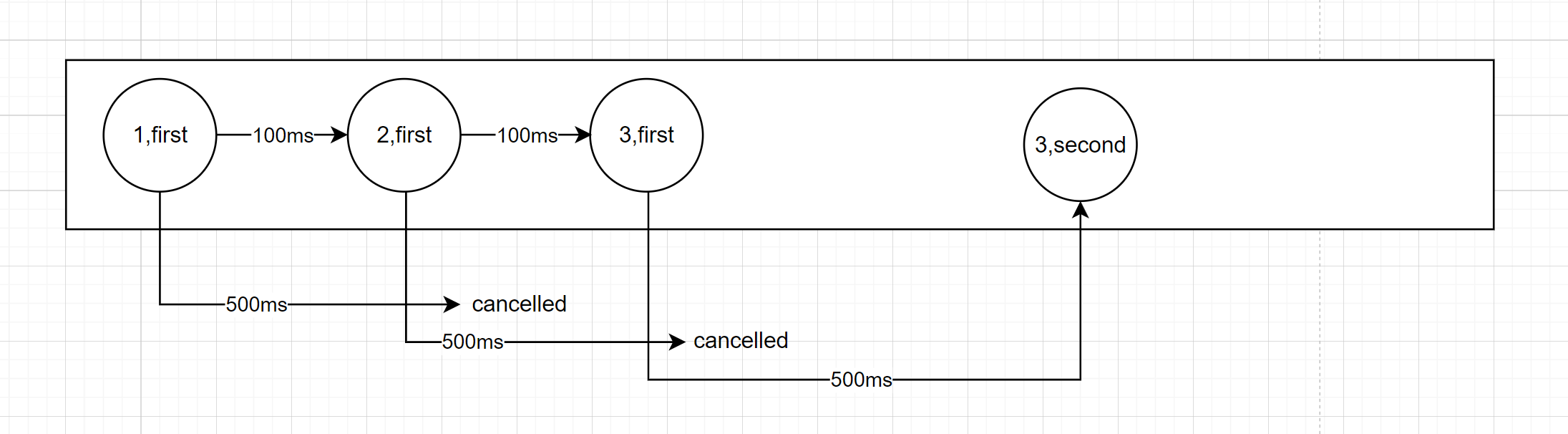
1: First at 164 ms from start
2: First at 283 ms from start
3: First at 385 ms from start
3: Second at 885 ms from start
Flow exceptions
Flow collection can complete with an exception when an emitter or code inside the operators throw an exception. There are several ways to handle these exceptions.
Collector try and catch
A collector can use Kotlin's try/catch block to handle exceptions:
fun simple(): Flow<Int> = flow {
for (i in 1..3) {
println("Emitting $i")
emit(i) // emit next value
}
}
fun main() = runBlocking<Unit> {
try {
simple().collect { value ->
println(value)
check(value <= 1) { "Collected $value" }
}
} catch (e: Throwable) {
println("Caught $e")
}
}This code successfully catches an exception in collect terminal operator and, as we see, no more values are emitted after that:
Emitting 1
1
Emitting 2
2
Caught java.lang.IllegalStateException: Collected 2
Everything is caught
The previous example actually catches any exception happening in the emitter or in any intermediate or terminal operators. For example, let's change the code so that emitted values are mapped to strings, but the corresponding code produces an exception:
fun simple(): Flow<String> =
flow {
for (i in 1..3) {
println("Emitting $i")
emit(i) // emit next value
}
}
.map { value ->
check(value <= 1) { "Crashed on $value" }
"string $value"
}
fun main() = runBlocking<Unit> {
try {
simple().collect { value -> println(value) }
} catch (e: Throwable) {
println("Caught $e")
}
}This exception is still caught and collection is stopped:
Emitting 1
string 1
Emitting 2
Caught java.lang.IllegalStateException: Crashed on 2
flow가 처리되면서 map에서 error를 발생시키면 flow가 모두 처리되지않은채로 exception 처리된다.
Exception transparency
But how can code of the emitter encapsulate its exception handling behavior?
Flows must be transparent to exceptions and it is a violation of the exception transparency to emit values in the flow { ... } builder from inside of a try/catch block. This guarantees that a collector throwing an exception can always catch it using try/catch as in the previous example.
try-catch 블록 내부에서 flow { } 빌더를 사용하여 values를 emit 하는 것은 exception transparency를 위반하는 것이며, Flows는 반드시 예외에 transparent해야한다.
transparency는 downstream에서 발생한 에러를 미리 처리하여 collector가 모르게 되는 상황이 되면 안된다는 의미이다.
이러한 transparency는 collector가 던지는 예외는 항상 catch할 수 있다는 이전 예외와 같은 상황을 보장하는 역할을 한다.
The emitter can use a catch operator that preserves this exception transparency and allows encapsulation of its exception handling. The body of the catch operator can analyze an exception and react to it in different ways depending on which exception was caught:
emitter 는 catch 라는 operator를 사용하여 exception transparency를 보존하는 방식을 사용할 수 있으며, exception 사용에 있어 encapsulation한 방식을 제공한다. 따라서 catch의 body는 exception을 analyze 할 수 있도록 해주며 예외가 캡쳐 되는 다음과 같은 다양한 상황에 대응하게 된다.
- Exceptions can be rethrown using throw.
- Exceptions can be turned into emission of values using emit from the body of catch.
- Exceptions can be ignored, logged, or processed by some other code.
- 예외는 throw를 사용하여 rethown할 수 있다.
- 예외는 catch의 body에서 emit을 사용하여 값의 emission으로 전환할 수 있다
- 예외는 ignored, logged, 하거나 다른 코드로 process할 수 있다
For example, let us emit the text on catching an exception:
simple()
.catch { e -> emit("Caught $e") } // emit on exception
.collect { value -> println(value) }The output of the example is the same, even though we do not have try/catch around the code anymore.
try/catch 없어도 output example은 같은 결과를 나타낸다.
Emitting 1
string 1
Emitting 2
Caught java.lang.IllegalStateException: Crashed on 2
Transparent catch
The catch intermediate operator, honoring exception transparency, catches only upstream exceptions (that is an exception from all the operators above catch, but not below it). If the block in collect { ... } (placed below catch) throws an exception then it escapes:
transparency 를 존중하는 catch operator 매개자는 only upstream exception만 catch하며(즉, 모든 operators로부터의 예외는 above catch이며, below it이 아니다) 만약에 collect { } 안의 블록(catch 아래에 위치한)이 예외를 throw하는 경우에는 the block은 escape하게 된다. 아래 예제를 참고하면,
fun simple(): Flow<Int> = flow {
for (i in 1..3) {
println("Emitting $i")
emit(i)
}
}
fun main() = runBlocking<Unit> {
simple()
.catch { e -> println("Caught $e") } // does not catch downstream exceptions
.collect { value ->
check(value <= 1) { "Collected $value" }
println(value)
}
}
위와 같은 상황에 catch는 check에서 value가 2인 경우에 발생하는 collect 쪽( catch operator의 below)에서 동작하지 않는다.
Emitting 1
1
Emitting 2
Exception in thread "main" java.lang.IllegalStateException: Collected 2
at FileKt$main$1$invokeSuspend$$inlined$collect$1.emit (Collect.kt:135)
at kotlinx.coroutines.flow.FlowKt__ErrorsKt$catchImpl$$inlined$collect$1.emit (Collect.kt:136)
at kotlinx.coroutines.flow.internal.SafeCollectorKt$emitFun$1.invoke (SafeCollector.kt:15)
Catching declaratively. 선언적인 catching
We can combine the declarative nature of the catch operator with a desire to handle all the exceptions, by moving the body of the collect operator into onEach and putting it before the catch operator. Collection of this flow must be triggered by a call to collect() without parameters:
구글 자동 번역 : 수집 연산자의 본문을 onEach로 이동하고 catch 연산자 앞에 배치하여 catch 연산자의 선언적 특성을 모든 예외를 처리하려는 욕구와 결합할 수 있습니다. 이 흐름의 수집은 매개변수 없이 collect() 호출에 의해 트리거되어야 합니다
즉, onEach와 below단에서의 catch 결합으로 효과적인 예외처리를 할 수 있다. collect를 사용하여 catch를 operating 시킬 수 있다.
simple()
.onEach { value ->
check(value <= 1) { "Collected $value" }
println(value)
}
.catch { e -> println("Caught $e") }
.collect()Emitting 1
1
Emitting 2
Caught java.lang.IllegalStateException: Collected 2
Flow completion
When flow collection completes (normally or exceptionally) it may need to execute an action. As you may have already noticed, it can be done in two ways: imperative or declarative.
flow collection은 action의 execute되어야만이 (normal이든, exception이든 간에) complete된다
imperative 방식과 declarative 방식이 있다.
Imperative finally block
In addition to try/catch, a collector can also use a finally block to execute an action upon collect completion.
fun simple(): Flow<Int> = (1..3).asFlow()
fun main() = runBlocking<Unit> {
try {
simple().collect { value -> println(value) }
} finally {
println("Done")
}
}1
2
3
Done
Declarative handling
For the declarative approach, flow has onCompletion intermediate operator that is invoked when the flow has completely collected.
The previous example can be rewritten using an onCompletion operator and produces the same output:
simple()
.onCompletion { println("Done") }
.collect { value -> println(value) }
위와 같이 선언적인 방식(onCompletion)을 통해 complete가 된 상황에서 이루어질 일을 upstream에서 미리 정의할 수 있다.
The key advantage of onCompletion is a nullable Throwable parameter of the lambda that can be used to determine whether the flow collection was completed normally or exceptionally. In the following example the simple flow throws an exception after emitting the number 1:
fun simple(): Flow<Int> = flow {
emit(1)
throw RuntimeException()
}
fun main() = runBlocking<Unit> {
simple()
.onCompletion { cause -> if (cause != null) println("Flow completed exceptionally") }
.catch { cause -> println("Caught exception") }
.collect { value -> println(value) }
}As you may expect, it prints:
1
Flow completed exceptionally
Caught exceptionThe onCompletion operator, unlike catch, does not handle the exception. As we can see from the above example code, the exception still flows downstream. It will be delivered to further onCompletion operators and can be handled with a catch operator.
the exception는 downstream flow인데, 이것이 onCompletion operator에 전달되어 catch operator를 handle할 수 있게 된다.
즉 collect시 flow에 throw되는 simple의 예외는 onCompletion operator block에서 catch block의 동작을 수집하여 처리할 수 있도록한다. (단지, try/catch용도로 쓰고자한다면, onCompletion operator없이 catch operator만 써도 무방하다)
Successful completion
Another difference with catch operator is that onCompletion sees all exceptions and receives a null exception only on successful completion of the upstream flow (without cancellation or failure).
onCompletion 은 catch와는 다르게 모든 exception을 확인하고, upstream flow의 successful completion에서만 null exception을 receive한다.
fun simple(): Flow<Int> = (1..3).asFlow()
fun main() = runBlocking<Unit> {
simple()
.onCompletion { cause -> println("Flow completed with $cause") }
.collect { value ->
check(value <= 1) { "Collected $value" }
println(value)
}
}We can see the completion cause is not null, because the flow was aborted due to downstream exception:
1
Flow completed with java.lang.IllegalStateException: Collected 2
Exception in thread "main" java.lang.IllegalStateException: Collected 2Imperative versus declarative
Now we know how to collect flow, and handle its completion and exceptions in both imperative and declarative ways. The natural question here is, which approach is preferred and why? As a library, we do not advocate for any particular approach and believe that both options are valid and should be selected according to your own preferences and code style.
두 옵션 모두 적절한 상황에 잘 사용하면 된다.
Launching flow
It is easy to use flows to represent asynchronous events that are coming from some source. In this case, we need an analogue of the addEventListener function that registers a piece of code with a reaction for incoming events and continues further work. The onEach operator can serve this role. However, onEach is an intermediate operator. We also need a terminal operator to collect the flow. Otherwise, just calling onEach has no effect.
소스로부터 오는 asynchronous event 를 처리하는 쉬운 방법은 addEventListener fucntion과 같은 analogue를 사용하는 것이다. 이러한 역할은 onEach Operator를 통해 수행할 수 있으며, collect 를 호출하여 onEach를 effective하게 만든다.
If we use the collect terminal operator after onEach, then the code after it will wait until the flow is collected:
// Imitate a flow of events
fun events(): Flow<Int> = (1..3).asFlow().onEach { delay(100) }
fun main() = runBlocking<Unit> {
events()
.onEach { event -> println("Event: $event") }
.collect() // <--- Collecting the flow waits
println("Done")
}As you can see, it prints:
Event: 1
Event: 2
Event: 3
Done
The launchIn terminal operator comes in handy here. By replacing collect with launchIn we can launch a collection of the flow in a separate coroutine, so that execution of further code immediately continues:
fun main() = runBlocking<Unit> {
events()
.onEach { event -> println("Event: $event") }
.launchIn(this) // <--- Launching the flow in a separate coroutine
println("Done")
}launchIn operator를 사용하여 flow collecting시 독립된 코루틴이 시작되도록 할 수 있다. 이는 further code가 즉시 실행할 수 있도록 해준다.
The required parameter to launchIn must specify a CoroutineScope in which the coroutine to collect the flow is launched. In the above example this scope comes from the runBlocking coroutine builder, so while the flow is running, this runBlocking scope waits for completion of its child coroutine and keeps the main function from returning and terminating this example.
luanchIn은 CoroutineScope를 특정해주는 파라미터가 필요하다. 위 예제에서는 runBlocking coroutine builder가 this로 들어가서 동작하며, flow 가 running할때 runBlocking Scope은 wait for completion of its child coroutine 이므로, main fuction이 rerturning하여 terminating되지 않도록 막아준다.
In actual applications a scope will come from an entity with a limited lifetime. As soon as the lifetime of this entity is terminated the corresponding scope is cancelled, cancelling the collection of the corresponding flow. This way the pair of onEach { ... }.launchIn(scope) works like the addEventListener. However, there is no need for the corresponding removeEventListener function, as cancellation and structured concurrency serve this purpose.
이러한 코루틴범위에 대한 지정은 cancel을 따로 관리할 필요 없이 coroutine 수명주기에 맞게 event를 listening하도록 해준다. 즉, removeEventListener와 같은 cancellation에 대한 고려가 의미 없다는 뜻이다.
Note that launchIn also returns a Job, which can be used to cancel the corresponding flow collection coroutine only without cancelling the whole scope or to join it.
2022.10.30 보충 : 참고(https://developer88.tistory.com/450)
flow는 basically cold State로 정의되어 있고, 이를 보강하기 위한 하나의 side way로 launchIn을 제공한다. 즉 collect대신 launchIn을 사용하게 되면 event Listener와 같은 동작을 depends on coroutine lifecycle 하여 operating할 수 있음을 알수 있다.

Flow cancellation checks
For convenience, the flow builder performs additional ensureActive checks for cancellation on each emitted value. It means that a busy loop emitting from a flow { ... } is cancellable:
fun foo(): Flow<Int> = flow {
for (i in 1..5) {
println("Emitting $i")
emit(i)
}
}
fun main() = runBlocking<Unit> {
foo().collect { value ->
if (value == 3) cancel()
println(value)
}
}We get only numbers up to 3 and a CancellationException after trying to emit number 4:
Emitting 1
1
Emitting 2
2
Emitting 3
3
Emitting 4
Exception in thread "main" kotlinx.coroutines.JobCancellationException: BlockingCoroutine was cancelled;However, most other flow operators do not do additional cancellation checks on their own for performance reasons. For example, if you use IntRange.asFlow extension to write the same busy loop and don't suspend anywhere, then there are no checks for cancellation:
그러나 대부분의 flow operator는 additional cancellation check를 수행하지 않음에 유의하자.
All numbers from 1 to 5 are collected and cancellation gets detected only before return from runBlocking:
1
2
3
4
5
Exception in thread "main" kotlinx.coroutines.JobCancellationException: 위 예제를 보면 5까지 collect되고나서 cacellation이 get detect됨을 볼 수 있다.
Making busy flow cancellable
In the case where you have a busy loop with coroutines you must explicitly check for cancellation. You can add .onEach { currentCoroutineContext().ensureActive() }, but there is a ready-to-use cancellable operator provided to do that:
위의 경우를 대비해서, 명시적으로 cancellation에 대한 체크를 할 수 있는 operator가 존재한다
fun main() = runBlocking<Unit> {
(1..5).asFlow().cancellable().collect { value ->
if (value == 3) cancel()
println(value)
}
}With the cancellable operator only the numbers from 1 to 3 are collected:
1
2
3
Exception in thread "main" kotlinx.coroutines.JobCancellationException: BlockingCoroutine was cancelled;
Flow and Reactive Streams
For those who are familiar with Reactive Streams or reactive frameworks such as RxJava and project Reactor, design of the Flow may look very familiar.
Indeed, its design was inspired by Reactive Streams and its various implementations. But Flow main goal is to have as simple design as possible, be Kotlin and suspension friendly and respect structured concurrency. Achieving this goal would be impossible without reactive pioneers and their tremendous work. You can read the complete story in Reactive Streams and Kotlin Flows article.
While being different, conceptually, Flow is a reactive stream and it is possible to convert it to the reactive (spec and TCK compliant) Publisher and vice versa. Such converters are provided by kotlinx.coroutines out-of-the-box and can be found in corresponding reactive modules (kotlinx-coroutines-reactive for Reactive Streams, kotlinx-coroutines-reactor for Project Reactor and kotlinx-coroutines-rx2/kotlinx-coroutines-rx3 for RxJava2/RxJava3). Integration modules include conversions from and to Flow, integration with Reactor's Context and suspension-friendly ways to work with various reactive entities.
Rx 에서 영감과 도움을 많이 받아 구현했고, 상호호환성을 구현했다는 의미임.
그외 메소드들은 아래를 참고.
https://witcheryoon.tistory.com/292
Coroutines guide, kotlinx-coroutines-core / flow 정리
https://kotlin.github.io/kotlinx.coroutines/kotlinx-coroutines-core/ kotlinx-coroutines-core Core primitives to work with coroutines. Coroutine builder functions: Coroutine dispatchers implementing..
witcheryoon.tistory.com
'Programming Theory > 코루틴(Coruotine)' 카테고리의 다른 글
| Coroutines/Flow/Suspend fun Design Trial (0) | 2022.02.04 |
|---|---|
| Coroutines guide, kotlinx-coroutines-core / flow (0) | 2022.02.01 |
| kotlin Coroutine 정리(4, Coroutine Context and Dispatchers) (0) | 2020.09.22 |
| kotlin Coroutine 정리(3, Composing Suspending Functions) (0) | 2020.09.21 |
| Kotlin Coroutine 정리(2, Cancellation and Timeouts) (0) | 2020.09.17 |



